
Python中xml.etree.ElementTree的使用

xml.etree.ElementTree(简称ElementTree)是Python标准库中用于处理XML文件的模块。它提供了简洁且高效的API,适用于解析、创建和修改XML文档。在需要处理XML数据的场景中,比如配置文件、数据交换格
|
xml.etree.ElementTree(简称ElementTree)是Python标准库中用于处理XML文件的模块。它提供了简洁且高效的API,适用于解析、创建和修改XML文档。在需要处理XML数据的场景中,比如配置文件、数据交换格式、Web服务响应等,ElementTree都是非常实用的工具。 一、基本使用场景
二、核心API与用法1. 解析XML文档解析字符串形式的XML:
输出:
解析XML文件:
输出:
2. 创建XML文档
生成的output.xml内容:
3. 修改XML文档修改现有元素的文本内容:
output_modified.xml内容:
4. 搜索与遍历XML树遍历所有子元素:
输出:
查找特定元素:
输出:
三、进阶用法1. 处理带有命名空间的XML命名空间在复杂XML文档中非常常见,用于区分不同元素的作用域。 解析带有命名空间的XML:
输出:
2. 使用XPath查找元素虽然ElementTree本身不支持完整的XPath语法,但提供了类似的路径查找功能。
输出:
3. 批量处理和转换XML当需要处理大量的XML数据时,可以利用生成器或者批量处理方法来提高效率。
四、常用技巧1. 使用生成器高效解析大文件如上所述,使用iterparse()和生成器可以有效节省内存并提高处理速度,适用于大文件的解析。 2. 自动缩进与格式化输出默认情况下,ElementTree生成的XML是无缩进的,可以通过手动调整生成XML的格式来使其更具可读性。
生成的output_pretty.xml内容:
3. 安全处理外部实体在处理来自不受信任源的XML数据时,最好禁用外部实体,以防止XML外部实体注入(XXE)攻击。
defusedxml库提供了更安全的XML解析方法,防止常见的安全漏洞。 |
您可能感兴趣的文章 :

-
Python pip更换清华源镜像
在安装Python库时使用清华源镜像是为了改善库的下载速度和稳定性 地址:https://pypi.tuna.tsinghua.edu.cn/simple 命令安装 安装命令: 1 pip install 包 -
Python中xml.etree.ElementTree的使用
xml.etree.ElementTree(简称ElementTree)是Python标准库中用于处理XML文件的模块。它提供了简洁且高效的API,适用于解析、创建和修改XML文档。在需 -
python中concurrent.futures的具体使用
concurrent.futures是 Python 标准库中用于并行编程的高级模块,它提供了一种高级别的接口来管理线程和进程。通过这个模块,你可以轻松地利用 -
解决Python调用df.to_csv()出现中文乱码的问题
Python调用df.to_csv()出现中文乱码 1 2 3 4 df = pd.DataFrame(data=total_info, columns=[公司全名, 公司简称, 公司规模, 融资阶段, 区域, 职位名称, 工作经验 -
python实现列表推导式与生成器的介绍
列表推导式和生成器是 Python 中的两个非常有用的工具。它们可以帮助你以简洁和高效的方式创建和处理数据集合。了解它们的用法不仅可以 -
python关于图片和base64互转的三种方式
通过cv2进行转换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import cv2 import base64 import numpy as np def img_to_base64(img_array): # 传入图片为RGB格式numpy矩阵, -
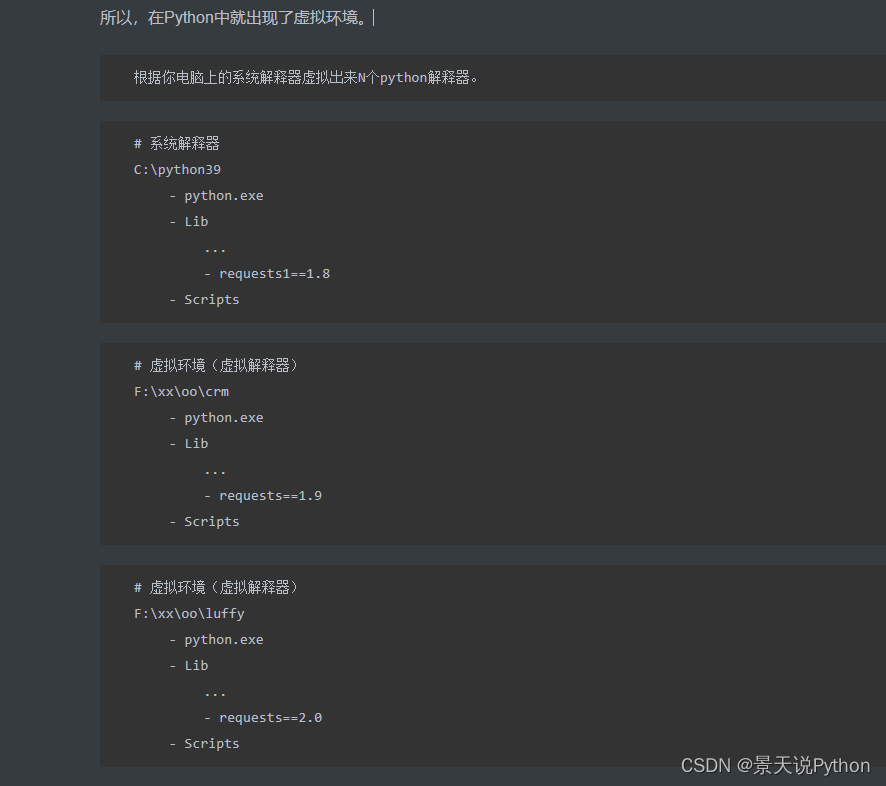
Python虚拟环境virtualenv安装的详细教程保姆级(Wi
虚拟环境安装 工作中我们经常会根据不同的项目切换不同的python环境,如果仅仅是在本地就安装一个python环境,项目移植也要重新配置环境




-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

