
PyTorch中torch.no_grad()用法举例

torch.no_grad() 是 PyTorch 中的一个上下文管理器,用于在上下文中临时禁用自动梯度计算。它在模型评估或推理阶段非常有用,因为在这些阶段,我们通常不需要计算梯度。禁用梯度计算可以减少
|
torch.no_grad() 是 PyTorch 中的一个上下文管理器,用于在上下文中临时禁用自动梯度计算。它在模型评估或推理阶段非常有用,因为在这些阶段,我们通常不需要计算梯度。禁用梯度计算可以减少内存消耗,并加快计算速度。 基本概念在 PyTorch 中,每次对 requires_grad=True 的张量进行操作时,PyTorch 会构建一个计算图(computation graph),用于计算反向传播的梯度。这对训练模型是必要的,但在评估或推理时不需要。因此,我们可以使用 torch.no_grad() 来临时禁用这些计算图的构建和梯度计算。 用法torch.no_grad() 的使用非常简单。只需要将不需要梯度计算的代码块放在 with torch.no_grad(): 下即可。 示例代码以下是一个使用 torch.no_grad() 的示例:
详细解释创建张量并设置 requires_grad=True:
创建一个包含三个元素的张量 x。 设置 requires_grad=True,告诉 PyTorch 需要为该张量记录梯度。 禁用梯度计算:
进入 torch.no_grad() 上下文,临时禁用梯度计算。 在上下文中,对 x 进行加法操作,得到新的张量 y。 打印 y,此时 y 的 requires_grad 属性为 False。 查看 requires_grad 属性:
打印 x 的 requires_grad 属性,仍然为 True。 打印 y 的 requires_grad 属性,已被禁用为 False。 使用场景模型评估在评估模型性能时,不需要计算梯度。使用 torch.no_grad() 可以提高评估速度和减少内存消耗。
模型推理在部署和推理阶段,只需要前向传播,不需要反向传播,因此可以使用 torch.no_grad()。
初始化权重或其他不需要梯度的操作 在某些初始化或操作中,不需要梯度计算。
小结torch.no_grad() 是一个用于禁用梯度计算的上下文管理器,适用于模型评估、推理等不需要梯度计算的场景。使用 torch.no_grad() 可以显著减少内存使用和加速计算。通过理解和合理使用 torch.no_grad(),可以使得模型评估和推理更加高效和稳定。 额外注意事项训练模式与评估模式: 在使用 torch.no_grad() 时,通常还会将模型设置为评估模式(model.eval()),以确保某些层(如 dropout 和 batch normalization)在推理时的行为与训练时不同。 嵌套使用: torch.no_grad() 可以嵌套使用,内层的 torch.no_grad() 仍然会禁用梯度计算。
恢复梯度计算: 在 torch.no_grad() 上下文管理器退出后,梯度计算会自动恢复,不需要额外操作。
通过合理使用 torch.no_grad(),可以在不需要梯度计算的场景中提升性能并节省资源。 |
您可能感兴趣的文章 :

-
PyTorch中torch.no_grad()用法举例
torch.no_grad() 是 PyTorch 中的一个上下文管理器,用于在上下文中临时禁用自动梯度计算。它在模型评估或推理阶段非常有用,因为在这些阶段 -
Python语言中的重要函数对象用法介绍
高级函数对象 lambda函数 python使用lambda来创建匿名函数。所谓匿名函数,就是不再使用像def语句这样标准的形式定义函数。 1 lambda [arg1,[arg -
Flask创建并运行数据库迁移的实现过程介绍
1. 安装必要的包 首先,确保已经安装了Flask以及Flask-SQLAlchemy(用于数据库操作)和Flask-Migrate(用于数据库迁移)。如果尚未安装,可以通过 -
Python中的Popen函数demo演示
1. 基本知识 在Python中,Popen 是 subprocess 模块中的一个函数,它用于创建一个子进程并与其进行通信 subprocess.Popen():Popen 类用于创建和管理子 -
Python获取Excel文件行数的方法
在数据分析和自动化办公领域,Python 因其简洁的语法和强大的库支持而广受欢迎。特别是当涉及到处理 Excel 文件时,Python 提供了多种库来 -
Pycharm中配置使用Anaconda的虚拟环境进行项目开发
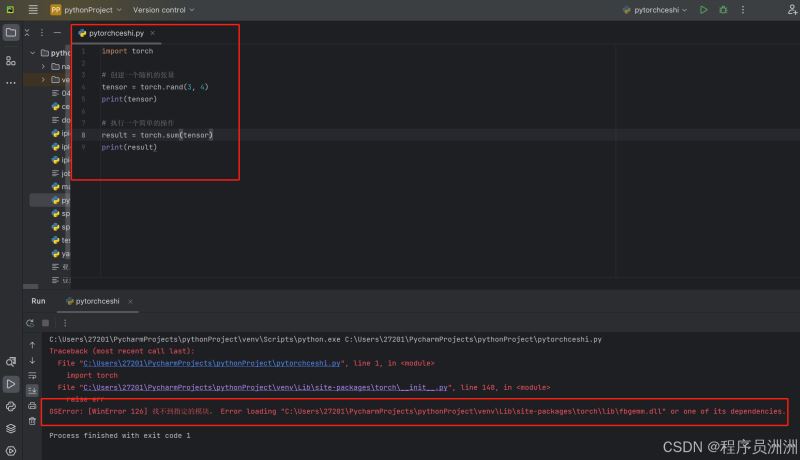
一、检查torch环境 今天在一台电脑上跑环境的时候,发现已经装了Pytorch了,但是运行没有用。 提示报错:OSError: [WinError 126] 找不到指定的模 -
python中pywebview框架使用方法记录
pywebview是python的一个库,类似于flask框架,这也是用来构建网页的软件包,它的特点就是不用更多的和html语言和js语言,更多的使用python语言 -
Python报错ValueError: cannot convert float NaN to integer的解
在Python编程中,我们经常需要处理各种数据类型,包括浮点数和整数。然而,有时候我们可能会遇到一些意外的情况,比如将一个包含NaN(



-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

