
Python图片文字识别与提取介绍

在工作中,有时候会有大量的截图、拍照数据需要提取,传统只能人工录入。但随着人工智能的发展,OCR技术已经可以实现了图片的文字识别,本节就讲讲如何安装部署文字识别环境,并进行
|
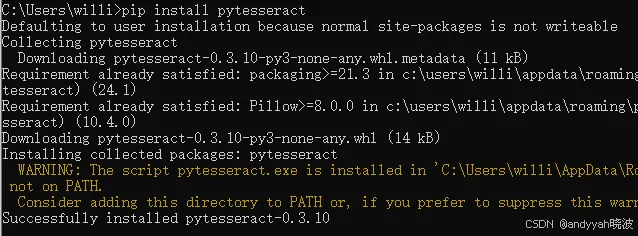
在工作中,有时候会有大量的截图、拍照数据需要提取,传统只能人工录入。但随着人工智能的发展,OCR技术已经可以实现了图片的文字识别,本节就讲讲如何安装部署文字识别环境,并进行文字识别实战。 <1> 前置条件1、掌握Python的基本知识 2、会使用pip安装扩展包 3、下载安装pytesseract软件 4、会配置Windows的环境变量。 <2> 使用pip安装pytesseract扩展包使用pytesseract包的第一步是使用pip安装该软件包。在命令提示符环境中,输入如下指令:
等待上述指令提示安装安装即可,如果出错,大概率是你的网络问题。如下:
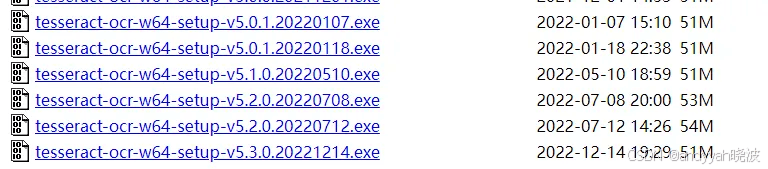
<3> 安装window配套软件包登录https://digi.bib.uni-mannheim.de/tesseract/网站,下载对应版本的软件。如下:
然后打开软件,开始软件的安装。如下先选择安装的语言,建议默认English即可,因为改为其它语言可能出现意想不到的错误。点击OK即可。
出现如下界面,点击Next即可。
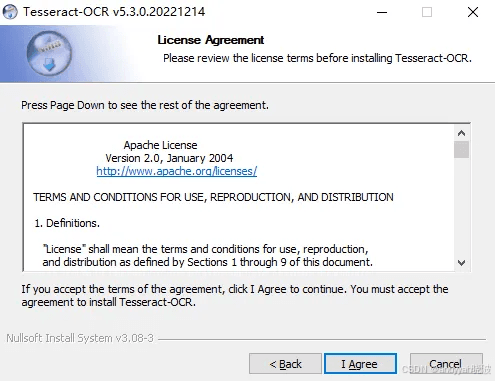
这里会出现License Agreement,这是一个授权条款,点击I Agree即可,如下:
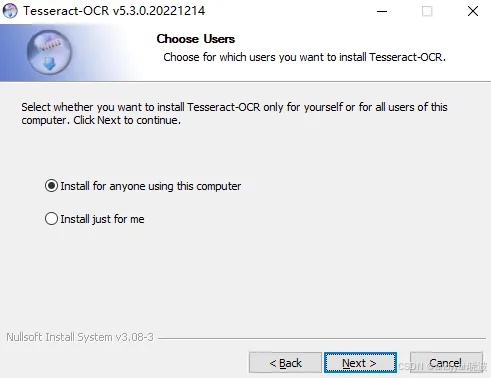
出现Choose Users界面,意思是你安装的软件谁可以用。建议默认,如果选择just for me会将软件安装到用户目录下。这里直接点击Next即可。
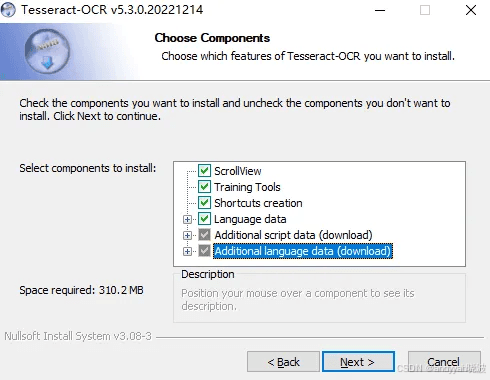
接下来是Choose Components,即选择组件。默认支持英文、数字的识别,如果要支持中文识别需要勾选Additional script data(han开头的4个)和Additional language data(chinese开头的4个)两项的中文内容。 然后点击Next,如下:
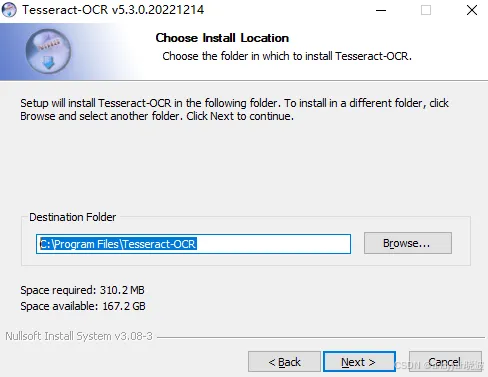
这里是安装目录,建议默认,直接点击Next即可。
接下来是选择是否将其添加到开始菜单,建议默认,直接点击Install。
然后等待安装完成,如下。
出现如下界面,表示安装完成。点击Next即可。
最后点击Finish按钮,结束程序安装。
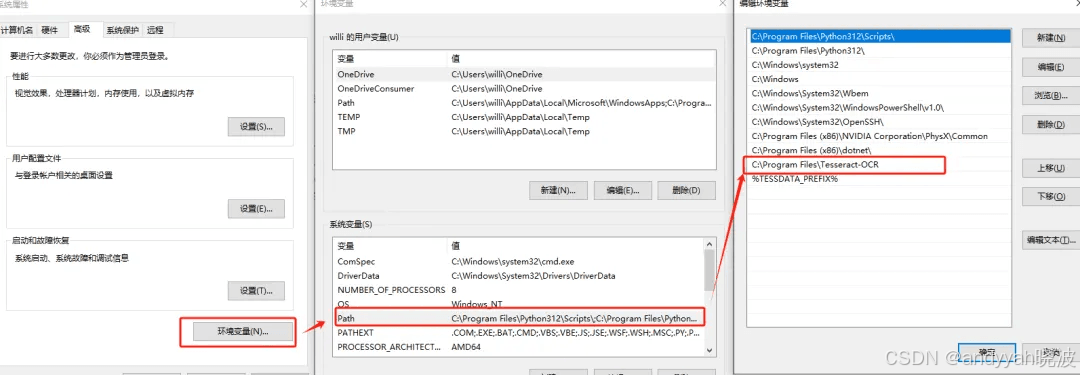
<4> 配置环境变量在Windows系统环境下使用,需要配置环境变量,主要涉及两个。 第一个是path变量需要新增tesseract的安装目录。我采用的默认路径,所以是:"C:\Program Files\Tesseract-OCR"。
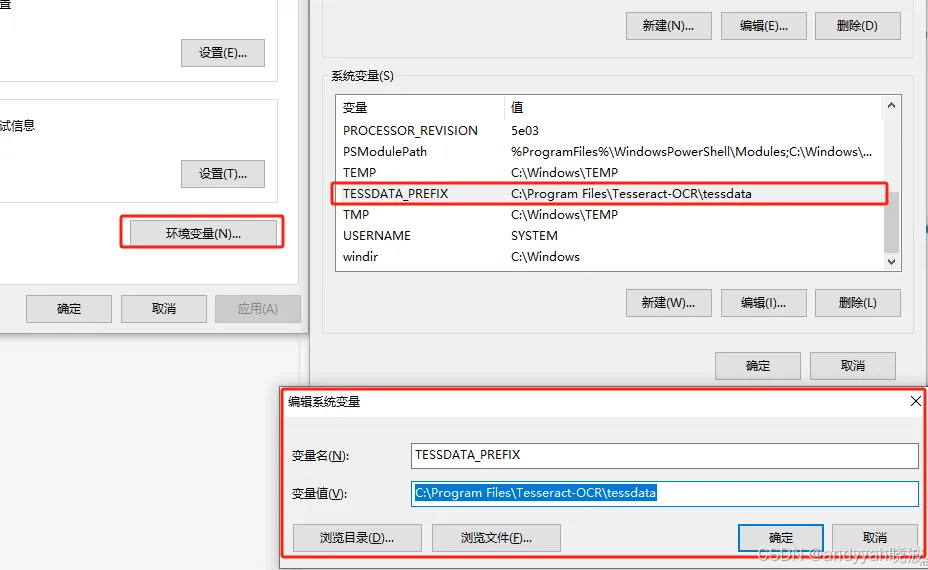
第二个是path变量需要新增tesseract的数据目录。如下:需要先新增一个变量名“TESSDATA_PREFIX”,变量值设置为:"安装路径\tessdata"。我采用的默认路径,所以是:"C:\Program Files\Tesseract-OCR\tessdata",如下:
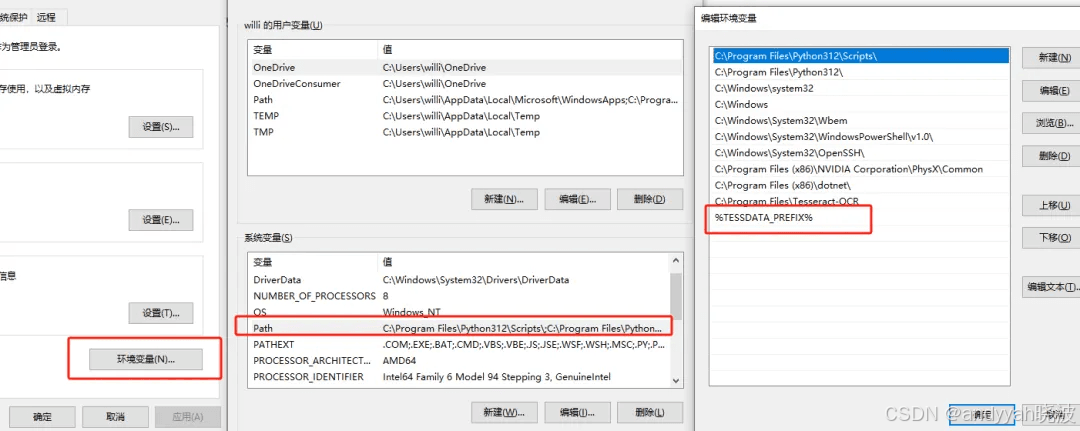
然后将新建的变量名添加到path变量列表中,如下:
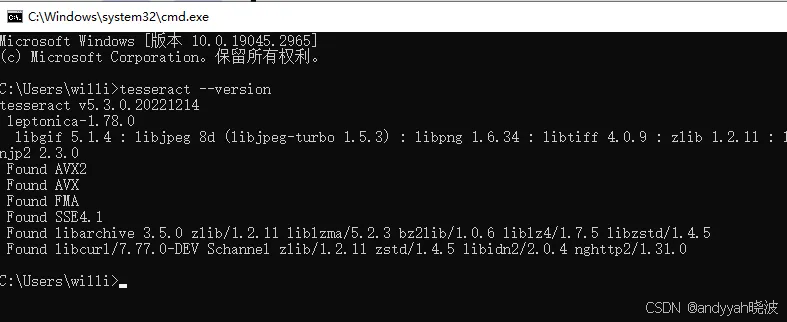
完成上述步骤后,需要重启电脑,否则接下来的步骤可能会失效。 验证是否安装成功,在命令提示符下输入tesseract --version,如果出现如下类似信息即表示成功,否则配置失败。
<5> 图片文字识别现在有了环境之后,小编就随便在网上找一个图来测试一下,看看效果如何,下面是在随便找的一个路牌图片。
写一个字符提取脚本,如下:
上述代码中,除了我们安装的包pytesseract外,还使用了PIL包,主要是利用PIL.Image完成图片的读取,这里可以不必理会,按照给定的语法使用就行。 利用该代码,输入的结果如下:
从识别的结果来看,能够识别部分文字,但对于框框内的文字识别出现了错误。对于此类问题需要对代码进行适当调优,从而去除框框的影响,有兴趣的小伙伴可以继续深入研究。 |


您可能感兴趣的文章 :

-
解决遇到:PytorchStreamReader failed reading zip archive:f
遇到 PytorchStreamReader failed reading zip archive: failed finding central directory 错误 是由于在读取PyTorch模型时出现的问题。 这个错误通常发生在模型文 -
PyTorch中torch.no_grad()用法举例
torch.no_grad() 是 PyTorch 中的一个上下文管理器,用于在上下文中临时禁用自动梯度计算。它在模型评估或推理阶段非常有用,因为在这些阶段 -
Python语言中的重要函数对象用法介绍
高级函数对象 lambda函数 python使用lambda来创建匿名函数。所谓匿名函数,就是不再使用像def语句这样标准的形式定义函数。 1 lambda [arg1,[arg -
Flask创建并运行数据库迁移的实现过程介绍
1. 安装必要的包 首先,确保已经安装了Flask以及Flask-SQLAlchemy(用于数据库操作)和Flask-Migrate(用于数据库迁移)。如果尚未安装,可以通过 -
Python中的Popen函数demo演示
1. 基本知识 在Python中,Popen 是 subprocess 模块中的一个函数,它用于创建一个子进程并与其进行通信 subprocess.Popen():Popen 类用于创建和管理子 -
Python获取Excel文件行数的方法
在数据分析和自动化办公领域,Python 因其简洁的语法和强大的库支持而广受欢迎。特别是当涉及到处理 Excel 文件时,Python 提供了多种库来 -
Pycharm中配置使用Anaconda的虚拟环境进行项目开发
一、检查torch环境 今天在一台电脑上跑环境的时候,发现已经装了Pytorch了,但是运行没有用。 提示报错:OSError: [WinError 126] 找不到指定的模 -
python中pywebview框架使用方法记录
pywebview是python的一个库,类似于flask框架,这也是用来构建网页的软件包,它的特点就是不用更多的和html语言和js语言,更多的使用python语言 -
Python报错ValueError: cannot convert float NaN to integer的解
在Python编程中,我们经常需要处理各种数据类型,包括浮点数和整数。然而,有时候我们可能会遇到一些意外的情况,比如将一个包含NaN(



-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

