
python解决中文乱码问题的方法介绍

1、demo.py 文件和编码声明都为 GBK 这种方法比较笨,就是把 demo.py 文件改为 GBK 存储,而且编码声明也是GBK,个人不推荐。 1 2 3 4 # encoding:gbk s = 中文 print s print repr(s) 2、中文用 unicode 表示 只要
|
1、demo.py 文件和编码声明都为 GBK 这种方法比较笨,就是把 demo.py 文件改为 GBK 存储,而且编码声明也是GBK,个人不推荐。
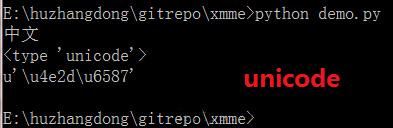
2、中文用 unicode 表示 只要在中文前面加上个小u标记,后面的中文就用 unicode 存储了。
cmd 下是可以打印 unicode 字符的,如下:
3、把中文强制转换为GBK或者unicode编码 强制转换为unicode编码,在 Python 中编码是可以互相转换的,比如从utf-8转换为gbk,不同编码之间不能直接转换,需要通过unicode字符集中间过渡下,从上面基础知识可知unicode是一种字符集,不属于编码,而utf-8是具体实现unicode思想的一种编码。utf-8转换为unicode是一种解码过程,通过decode可从utf-8解码成unicode。
强制转换为gbk编码,上一步已经从utf-8转换为unicode了,从unicode是编码的过程,通过encode实现。
总结 windows cmd 窗口下不支持utf-8,想要显示中文必须转换为gbk或者unicode,而 Python idle 中这三种编码都支持。中文乱码的出现都是由于编码不一致导致的,存储的是用utf-8,打印的时候用gbk就会乱码了,所有要保证不乱码尽量保持统一,建议全部使用unicode。 decode 解码 从其它编码变成unicode叫解码,解码用的方法是decode,第一个参数为被解码的字符串原始编码格式,如果写错了也会报错。比如 s 是utf-8,用gbk去解码就会报错。
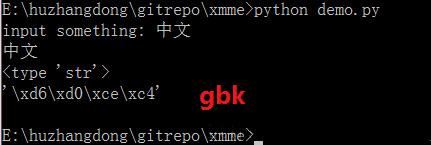
小提示 在 Python idle 和 cmd 下直接输入 s = "中文"会以 gbk 编码的,如果在文件中输入 s = "中文"且文件存储格式为utf-8,那么 s 是以utf-8编码存储的,有点不一样曾经踩过坑,及时 Python idle 成功了文件运行的时候也可能失败。 encode 编码 不可以直接从utf-8转换为gbk,必须经过unicode中间转换,这点很重要,被编码的原始字符串一定要为unicode,否则会报错。 raw_input raw_input 是获取用户输入值的,获取到的用户输入值和当前运行环境编码有关,比如 cmd 下默认编码是 gbk,那么输入的汉字就是以gbk编码,而不管 demo.py 文件编码格式和编码声明。
GBK 编码一个汉字两个字节,UTF-8 一个汉字通常3个字节。 细心的朋友已经注意了,raw_input的提示语我用的是英文,那改成中文看看,果真出现乱码了。
怎么办呢?把提示字符串强制为gbk编码就好,unicode和utf-8都不可以。
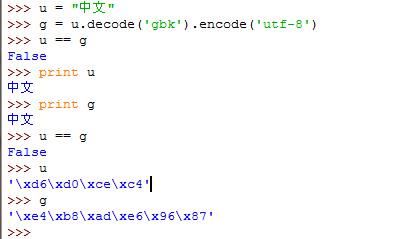
相等陷阱 “中文”这两个字符串用不同的编码存储是不一样的,utf-8编码和gbk编码存储的“中文”都不一样。
总结 想要不乱码,记住以下5点法则: (1)文件存储为utf-8格式,编码声明为utf-8,# encoding:utf-8。 (2)出现汉字的地方前面加 u。 (3)不同编码之间不能直接转换,要经过unicode中间跳转。 (4)cmd 下不支持utf-8编码。 (5)raw_input提示字符串只能为gbk编码。 |





您可能感兴趣的文章 :

-
python实现图像的随机增强变换
从文件夹中随机选择一定数量的图像,然后对每个选定的图像进行一次随机的数据增强变换。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 -

python解决中文乱码问题的方法介绍
1、demo.py 文件和编码声明都为 GBK 这种方法比较笨,就是把 demo.py 文件改为 GBK 存储,而且编码声明也是GBK,个人不推荐。 1 2 3 4 # encoding:g -
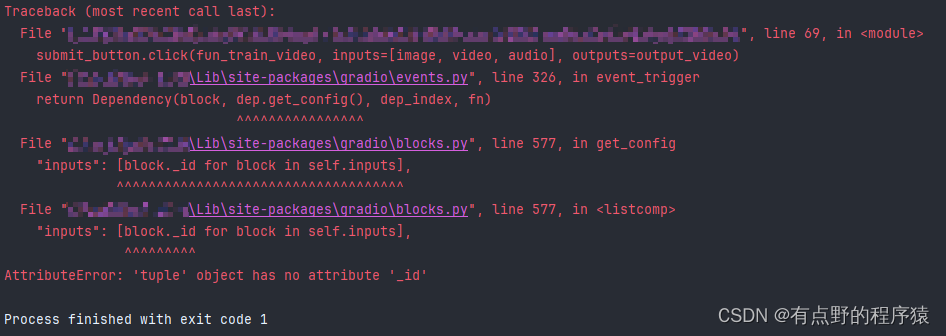
Gradio中Button用法及事件监听器click方法使用介绍
Gradio中Button用法及事件监听器click方法使用 瞎想乱记 事情是这样的:入职时面试的是Java,简历中写了会python,刚好最近有个小项目需要用 -
基于Python工具使用Web3.py以太坊智能合约开发的方
基于Python工具Web3.py进行以太坊智能合约开发 简介 智能合约是区块链技术的核心应用之一,它允许在没有中介的情况下,通过代码自动执行 -
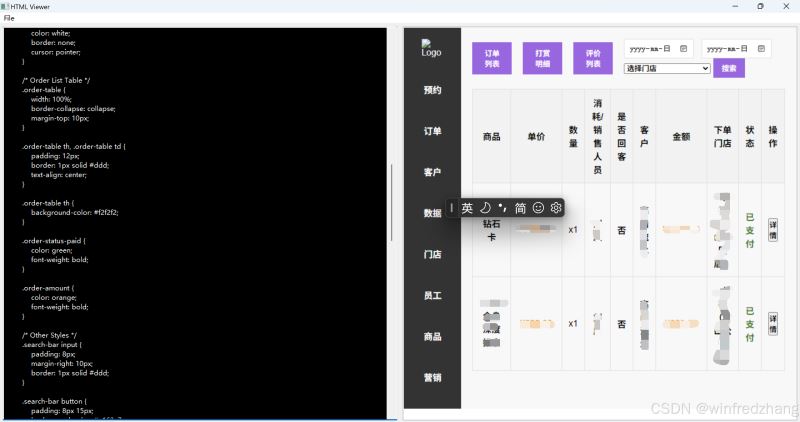
使用wxPython实现逐行加载HTML内容并实时显示效果
C:\pythoncode\new\simulateClaudeGenHtml.py 全部代码 1. 项目目标 本项目实现的目标是: 选择并打开一个 HTML 文件。 将 HTML 文件的内容逐行加载到一个 -
Python两条斜杠//的作用和用法
???? 一、认识两条斜杠 // 在Python编程语言中,两条斜杠//是一个算术运算符,称为整数除法运算符或地板除运算符。与常规的除法运算符/不 -
使用Poetry 进行Python 项目管理
现代软件开发中,Python 因其简洁和强大的功能而广受欢迎。然而,随着项目规模的扩大,依赖管理变得越来越复杂。Poetry,作为一个依赖管 -
Python如何使用pathlib模块处理文件路径
在Python中处理文件路径 下面将详细介绍如何使用pathlib模块来处理文件路径。我们将从创建Path对象、绝对路径与相对路径、访问文件路径分




-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

