
Python怎么获取HTTP请求的Response Body

在Python中进行网络编程和Web开发时,经常需要发送HTTP请求并处理服务器返回的响应。其中,获取响应体(Response Body)是常见的需求之一。本文将详细介绍在Python中如何获取HTTP请求的响应体,
|
在Python中进行网络编程和Web开发时,经常需要发送HTTP请求并处理服务器返回的响应。其中,获取响应体(Response Body)是常见的需求之一。本文将详细介绍在Python中如何获取HTTP请求的响应体,包括使用内置的urllib库、第三方库requests以及一些高级用法。通过丰富的案例和代码示例,帮助新手朋友更好地理解和掌握这一技能。 一、引言HTTP协议是Web开发中最重要的协议之一,它定义了客户端和服务器之间的通信方式。在HTTP请求和响应中,响应体包含了服务器返回给客户端的数据,这些数据可能是HTML文档、JSON对象、图片等。在Python中,有多种方法可以发送HTTP请求并获取响应体。 二、使用urllib库获取Response Bodyurllib是Python标准库中的一个模块,用于处理URL和HTTP请求。虽然urllib的API相对繁琐,但它是Python内置的,无需额外安装。 1. 基本用法下面是一个使用urllib发送GET请求并获取响应体的示例:
在这个例子中,我们首先创建了一个Request对象,然后使用urlopen函数发送请求。urlopen返回一个类文件对象,我们可以使用read方法读取响应体。注意,read方法返回的是字节数据,我们需要使用decode方法将其解码为字符串。 2. 发送POST请求使用urllib发送POST请求并获取响应体的示例如下:
在这个例子中,我们使用urlencode函数将数据编码为URL编码的字符串,并将其转换为字节数据。然后,我们将字节数据传递给Request对象的data参数,以发送POST请求。 三、使用requests库获取Response Bodyrequests是一个第三方库,用于发送HTTP请求。与urllib相比,requests的API更加简洁和易用。 1. 安装requests库在使用requests库之前,需要先安装它。可以使用pip命令进行安装:
2. 基本用法下面是一个使用requests发送GET请求并获取响应体的示例:
在这个例子中,我们直接调用requests.get函数发送GET请求,并获取响应体。response.text属性包含了响应体的字符串表示,无需手动解码。 3. 发送POST请求使用requests发送POST请求并获取响应体的示例如下:
在这个例子中,我们直接调用requests.post函数发送POST请求,并传递数据字典。response.text属性同样包含了响应体的字符串表示。 4. 处理JSON响应如果服务器返回的是JSON格式的响应体,我们可以使用response.json()方法将其解析为Python字典:
在这个例子中,response.json()方法将JSON响应体解析为Python字典,方便我们进行后续处理。 四、高级用法除了基本的GET和POST请求外,Python的HTTP客户端还支持更多高级功能,如处理请求头、设置超时、处理Cookies等。 1. 处理请求头我们可以使用headers参数传递请求头信息:
在这个例子中,我们传递了一个包含User-Agent的请求头信息。 2. 设置超时在发送请求时,我们可以设置超时时间,以避免请求长时间无响应:
在这个例子中,我们设置了超时时间为5秒。如果请求在5秒内没有响应,将抛出requests.exceptions.Timeout异常。 3. 处理Cookies我们可以使用cookies参数传递Cookies信息,或者使用Session对象来维护Cookies:
在这个例子中,我们首先使用cookies参数传递了Cookies信息。然后,我们使用Session对象来维护Cookies,这样在后续的请求中,Cookies会自动携带。 五、案例:爬取网页内容下面是一个使用requests库爬取网页内容并提取特定信息的示例:
在这个例子中,我们首先使用requests.get函数发送GET请求,并检查响应状态码是否为200(表示成功)。然后,我们使用BeautifulSoup库解析HTML内容,并提取网页标题。 六、总结本文详细介绍了在Python中如何获取HTTP请求的响应体。我们介绍了使用内置的urllib库和第三方库requests的基本用法和高级功能。通过丰富的案例和代码示例,我们展示了如何发送GET和POST请求、处理JSON响应、设置请求头、设置超时以及处理Cookies等。 |
您可能感兴趣的文章 :

-
Python怎么获取HTTP请求的Response Body
在Python中进行网络编程和Web开发时,经常需要发送HTTP请求并处理服务器返回的响应。其中,获取响应体(Response Body)是常见的需求之一。本 -
Python和Plotly实现3D图形绘制
在当今的数据分析和可视化领域,Python已经成为一种不可或缺的工具。其强大的数据处理能力和丰富的可视化库使得数据科学家和工程师们 -
Python默认参数的使用机制介绍
Python中,函数的默认参数是一种简化函数调用并增强灵活性的机制。默认参数允许我们在函数定义时为某些参数指定默认值,这样在调用函 -
使用Python创建自助抢单插件
在数字化时代,电子商务的迅猛发展使得消费者能够轻松地在线购买商品和服务。然而,随着竞争的加剧,许多热门商品和限量版商品在发 -
python实现图像的随机增强变换
从文件夹中随机选择一定数量的图像,然后对每个选定的图像进行一次随机的数据增强变换。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 -

python解决中文乱码问题的方法介绍
1、demo.py 文件和编码声明都为 GBK 这种方法比较笨,就是把 demo.py 文件改为 GBK 存储,而且编码声明也是GBK,个人不推荐。 1 2 3 4 # encoding:g -
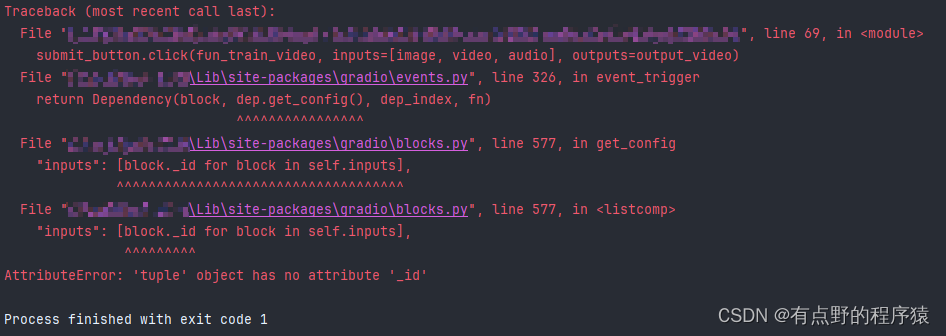
Gradio中Button用法及事件监听器click方法使用介绍
Gradio中Button用法及事件监听器click方法使用 瞎想乱记 事情是这样的:入职时面试的是Java,简历中写了会python,刚好最近有个小项目需要用



-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

