
使用python字典统计CSV数据的步骤和代码

1.用python字典统计CSV数据的步骤和代码示例 为了使用Python字典来统计CSV数据,我们可以使用内置的csv模块来读取CSV文件,并使用字典来存储统计信息。以下是一个详细的步骤和完整的代码示例
1.用python字典统计CSV数据的步骤和代码示例为了使用Python字典来统计CSV数据,我们可以使用内置的csv模块来读取CSV文件,并使用字典来存储统计信息。以下是一个详细的步骤和完整的代码示例: 1.1步骤(1)导入csv模块。 (2)打开CSV文件并读取数据。 (3)初始化一个空字典来存储统计信息。 (4)遍历CSV文件的每一行数据。 (5)对于每一行数据,根据需要选择一列或多列作为键(key),并统计其出现次数(或执行其他类型的统计)。 (6)将统计结果存储在字典中。 (7)关闭CSV文件。 (8)(可选)输出或处理统计结果。 1.2代码示例假设我们有一个CSV文件data.csv,内容如下:
我们想统计每个年龄(Age)的人数。
运行上述代码,我们将得到以下输出:
这样,我们就使用Python字典成功地统计了CSV数据中的年龄信息。 2.详细的代码示例展示我们展示几个不同的例子,这些例子展示了如何使用Python字典来统计CSV文件中的数据。 2.1统计每个名字的出现次数假设我们有一个CSV文件names.csv,内容如下:
我们想要统计每个名字的出现次数。
2.2统计每个年龄段的用户数量假设我们有一个CSV文件users.csv,内容如下:
我们想要统计18-24岁、25-30岁、31岁及以上每个年龄段的用户数量。
2.3统计每个性别在每个年龄段的用户数量假设我们有一个CSV文件users_advanced.csv,内容如下:
我们想要统计每个性别在每个年龄段(18-24岁、25-30岁、31岁及以上)的用户数量。
3.统计字典的缺点和局限统计字典(即使用Python字典来存储统计信息)在数据分析和处理中是一种非常有效的方法,但它也有一些潜在的缺点和局限性: (1)内存占用:字典在内存中存储键值对,当数据量非常大时,它们会占用相当多的内存。这可能会导致程序在内存有限的系统上运行缓慢或崩溃。 (2)稀疏性:如果统计的数据非常稀疏(即许多键在字典中只出现一次或根本不出现),则字典将包含大量的键值对,其中许多值都是1或0。这可能导致内存使用效率低下。 (3)不可排序:字典本身是无序的,尽管在Python 3.7+中插入顺序被保留(但这不应该被用作排序的依据)。如果我们需要按照特定的顺序遍历统计结果,我们可能需要额外的步骤来对字典的键或值进行排序。 (4)并发问题:在多线程或多进程环境中,直接修改字典可能会引发并发问题,如数据竞争和不一致的结果。在这种情况下,我们可能需要使用锁或其他同步机制来保护对字典的访问。 (5)不支持快速范围查询:字典不支持像列表或数组那样的范围查询。如果我们需要查找在某个范围内的所有键或值,我们可能需要遍历整个字典,这可能会很慢。 (6)无法直接进行数学运算:字典本身不支持数学运算(如加法、减法、乘法等)。如果我们需要对统计结果进行数学运算,我们可能需要将字典转换为其他数据结构(如NumPy数组或Pandas DataFrame),或者编写额外的代码来处理字典中的值。 (7)不支持多维索引:字典只能使用单个键来索引值。如果我们需要基于多个键来索引值(例如,在多维数据集中),我们可能需要使用嵌套字典或其他数据结构。 (8)可读性和可维护性:对于复杂的统计任务,使用字典可能会导致代码变得难以阅读和维护。在这种情况下,使用更高级的数据结构或库(如Pandas DataFrame)可能会更合适。 尽管有这些缺点,但字典在统计和数据处理中仍然是非常有用的工具。它们提供了灵活且高效的方式来存储和检索数据,并且对于许多常见任务来说已经足够了。然而,在设计我们的程序时,我们应该考虑我们的具体需求和环境,并选择最适合我们的数据结构和方法。 |
您可能感兴趣的文章 :

-
Python获取Windows桌面路径的三种方法
1 概述 因为某些原因,需要使用不同用户的 Windows 桌面路径,故无法对路径进行固定,可使用下列方法进行获取 2 方法 2.1 方法1:使用 os 模 -
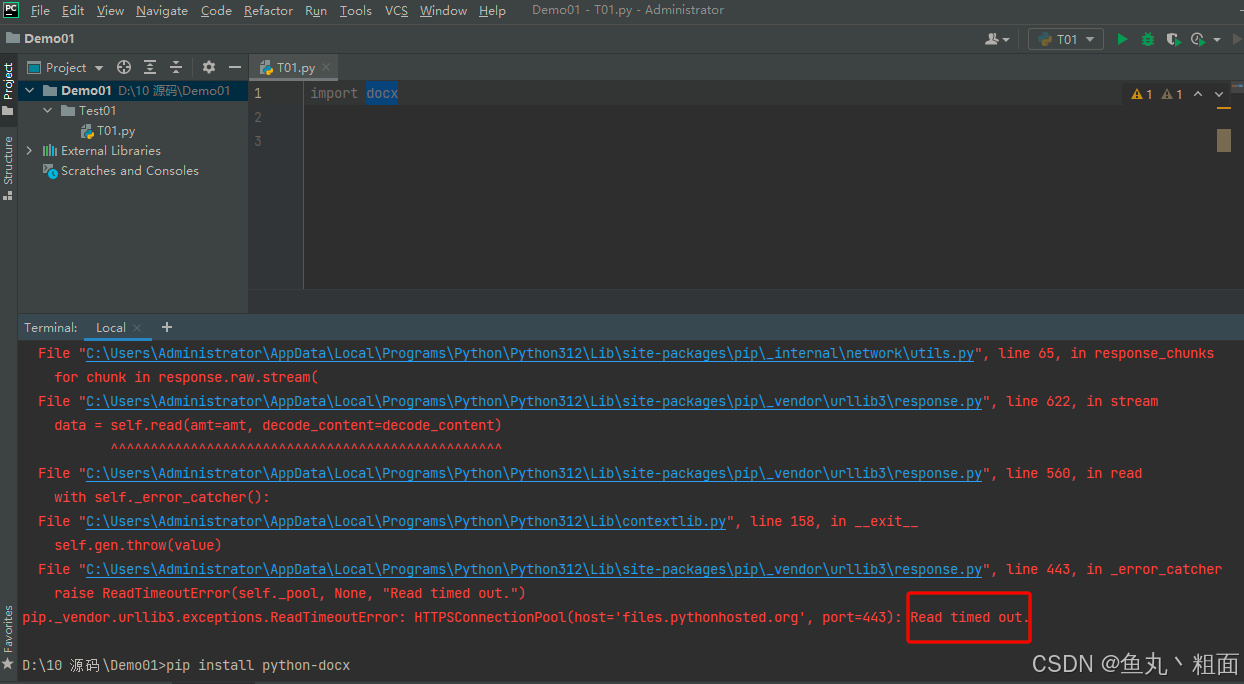
Python pip更换镜像源的步骤
1.1 默认镜像,速度慢,易报错 默认镜像,速度慢。在使用 pip 安装 Python 包时会默认从官方的 PyPI 镜像源(mirror source)下载文件,由于官方 -
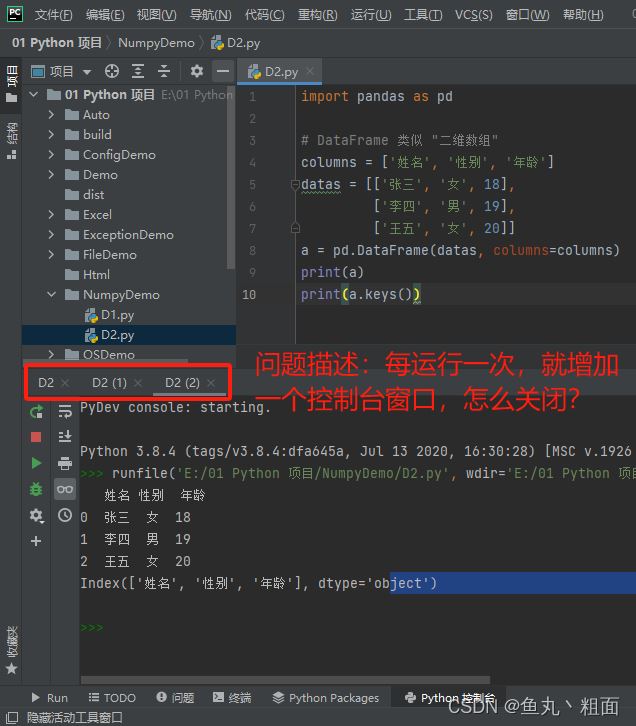
Pycharm关闭控制台多余窗口的解决办法
1 问题描述 2 解决办法 2.1 步骤1:编辑配置 菜单路径:运行【run】 - 编辑配置【Edit Configurations】 2.2 步骤2:使用 Python 控制台运行(取消勾 -
使用Python和FastAPI实现MinIO断点续传功能
在分布式存储和大数据应用中,断点续传是一个重要的功能,它允许大文件上传在中断后可以从中断点恢复,而不是重新上传整个文件。本 -
使用python字典统计CSV数据的步骤和代码
1.用python字典统计CSV数据的步骤和代码示例 为了使用Python字典来统计CSV数据,我们可以使用内置的csv模块来读取CSV文件,并使用字典来存储 -

Python爬虫中如何使用xpath解析HTML
你可能之前听说或用过其它的解析方式,像 Beautiful Soup,用的人好像也不少,但 xpath 与之相比,语法更简单,解析速度更快,就像正则表达 -
使用Python分析wireshark文件
1 pyshark库 支持wireshark的解析等。 安装pyshark 1 pip install pyshark 2 dpkt库 这也是一个用于分析pcap文件的库,是所有分析pcap库中最快的一个。 官 -
Python删除视频的某一段并保留其他时间段
要使用 Python 删除视频的某一段并保留其他时间段,可以借助 moviepy 库来实现。moviepy 是一个非常强大的视频处理库,可以轻松进行视频剪切 -

python中字典元素的创建、获取和遍历等字典
本文介绍了Python中的字典操作,包括字典的创建、元素获取(使用键和get()方法)、删除与清空(del和clear())、增加新键值对、修改已有值、 -
使用Python实现轻松调整视频的播放速度
要使用 Python 调整视频的播放速度,可以利用 moviepy 库中的 fx(特效)模块来实现这一功能。通过 moviepy.editor 中的 VideoFileClip 类和 fx.speedx



-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

