
Python如何使用组合方式构建复杂正则

正则写复杂了很麻烦,难写难调试,只需要两个函数,就能用简单正则组合构建复杂正则: 比如输入一个字符串规则,可以使用{name}引用前面定义的规则: 1 2 3 4 5 6 7 8 9 10 11 12 # rules definitio
|
正则写复杂了很麻烦,难写难调试,只需要两个函数,就能用简单正则组合构建复杂正则: 比如输入一个字符串规则,可以使用 {name} 引用前面定义的规则:
然后调用 regex_build 函数,将上面的规则转换成一个字典并输出: 结果:
用手写直接写是很难写出这么复杂的正则的,写出来也很难调试,而组合方式构建正则的话,可以将小的简单正则提前测试好,要用的时候再组装起来,就不容易出错,上面就是组装替换后的结果。 下面用里面的 url 这个规则来匹配一下:
输出:
可以取完整结果,也可以按照规则名字,取得里面具体某个部件得匹配结果。 这下可以方便的写复杂正则表达式了。 再 Python 的正则表达式里 {xxx} 是用来表示长度的,里面都是数字,如果里面是变量名的话不会和原有规则冲突,因此这个写法是安全的。 实现代码:
完事,主要逻辑 84 行代码。 |
您可能感兴趣的文章 :

-
基于Python制作一个全自动微信清粉小工具
在当今社交软件中,微信是最常用的通讯工具之一。然而,随着时间的推移,我们的好友列表中可能会出现一些不再活跃的账号,也就是我 -
YOLOv8模型pytorch格式转为onnx格式的步骤介绍
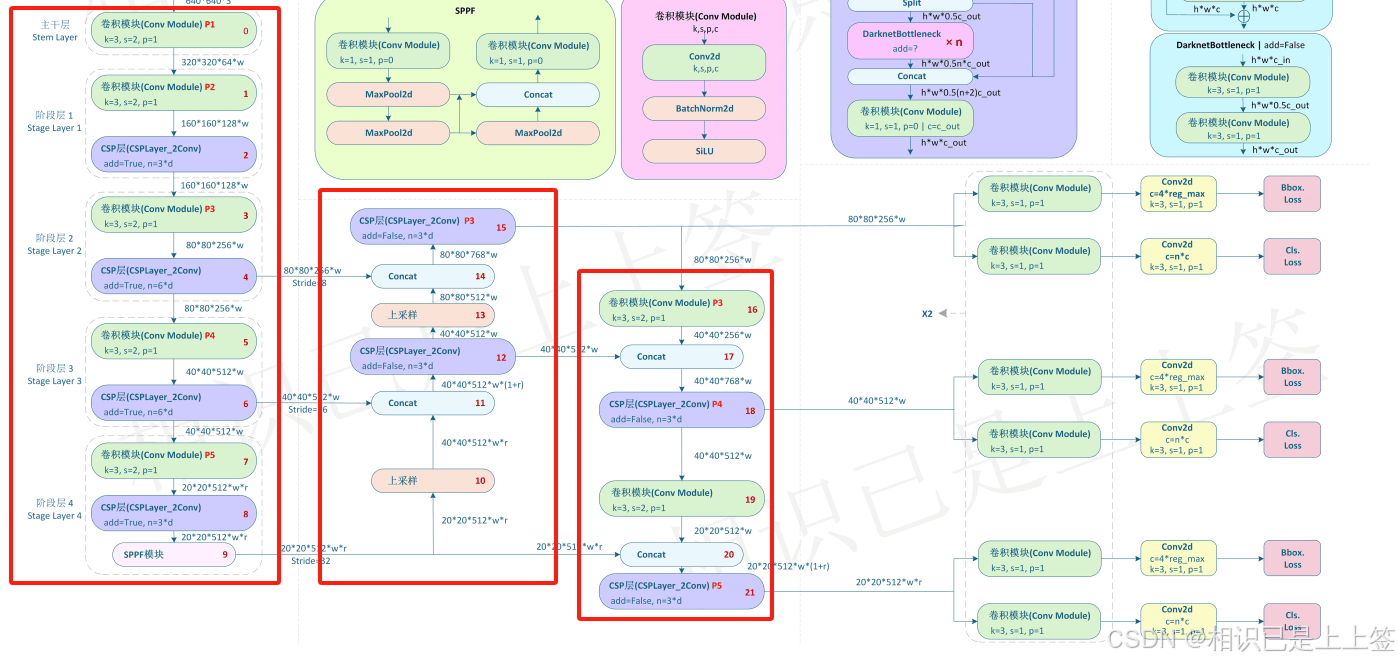
一、YOLOv8的Pytorch网络结构 yolov8网络从1-21层与pt文件相对应是BackBone和Neck模块,22层是Head模块。 二、转ONNX步骤 2.1 yolov8官方 1 2 3 4 5 6 7 8 9 -

Python中addict库使用Dict的类
from addict import Dict这行代码导入了 Dict 类,它来自于 addict 模块。在这个上下文中,addict 是一个 Python 库,它提供了一个名为 Dict 的类,用于 -
Python利用标签实现清理微信好友的自动化脚本
微信已经成为我们日常生活中不可或缺的社交工具。随着使用时间的增长,我们的微信好友列表可能会变得越来越臃肿。 在上一篇文章中, -
Python判断空的五种方法介绍
一、使用if语句判断 在Python中,可以使用if语句判断一个变量是否为空,若为空,则可以执行相应的操作。 此处判断的是var是否为None,如果 -
Python的json模块中json.load()和json.loads()的区别
json.load和json.loads都是Python的json模块中用于解析JSON数据的方法,但它们之间有一些重要的区别。 1. json.load json.load用于从一个文件对象中读取 -

Python遍历文件和文件路径拼接介绍
一、os.walk()文件(夹)读取 遍历指定路径下的所有文件和文件夹 示例代码如下 1 2 3 4 5 6 7 8 9 10 mdfFolder= D:\hanshan\MDF for root, dirs, files in os.w -
Python如何使用组合方式构建复杂正则
正则写复杂了很麻烦,难写难调试,只需要两个函数,就能用简单正则组合构建复杂正则: 比如输入一个字符串规则,可以使用{name}引用前 -
4个必学的Python自动化技巧
在当今快节奏的工作环境中,自动化是提升效率的重要手段。Python作为一种强大且易用的编程语言,在自动化领域有着广泛的应用。本文将 -
Python获取Windows桌面路径的三种方法
1 概述 因为某些原因,需要使用不同用户的 Windows 桌面路径,故无法对路径进行固定,可使用下列方法进行获取 2 方法 2.1 方法1:使用 os 模



-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

