
利用Python爬虫精准获取淘宝商品

在数字化时代,数据的价值日益凸显,尤其是在电子商务领域。淘宝作为中国最大的电商平台之一,拥有海量的商品数据,对于研究市场趋势、分析消费者行为等具有重要意义。本文将详细介
|
在数字化时代,数据的价值日益凸显,尤其是在电子商务领域。淘宝作为中国最大的电商平台之一,拥有海量的商品数据,对于研究市场趋势、分析消费者行为等具有重要意义。本文将详细介绍如何使用Python编写爬虫程序,精准获取淘宝商品详情信息。
环境准备在开始之前,我们需要准备以下环境和工具:
淘宝商品详情获取流程淘宝的商品详情页面通常是动态加载的,这意味着我们不能直接通过GET请求获取到完整的商品详情。我们需要模拟浏览器的行为,使用Selenium来获取动态加载的内容。 步骤1:模拟浏览器访问首先,我们需要模拟浏览器访问淘宝商品页面。这里我们使用Selenium WebDriver。
步骤2:解析商品详情一旦页面加载完成,我们可以使用Selenium提供的API来获取页面源码,并使用BeautifulSoup来解析页面,提取商品详情。
步骤3:处理反爬虫机制淘宝有复杂的反爬虫机制,我们需要采取一些措施来避免被封禁。
步骤4:数据存储获取到商品详情后,我们可以将其存储到本地文件或数据库中。
结语通过上述步骤,我们可以实现一个基本的淘宝商品详情爬虫。然而,需要注意的是,淘宝的反爬虫技术非常先进,频繁的爬取可能会导致IP被封禁。因此,在实际应用中,我们应当遵守淘宝的使用协议,合理合法地使用爬虫技术。 |

您可能感兴趣的文章 :

-
Python文件批量处理操作的实现
在日常的开发和数据处理过程中,我们可能会遇到需要对大量文件进行批量操作的场景。比如,批量重命名文件、批量移动文件、批量修改 -
python的三种等待方式及优缺点介绍
一、调用方式 1.强制等待 调用time模块,使用time.sleep(n),强制等待n秒 2.隐式等待 implicitly_wait(n),设置隐式等待最大时间n秒,等待元素加载完 -
Python利用xmltodict实现字典和xml互相转换的代码
xmltodict简介 概念 xmltodict是Python中用于处理XML数据的模块,它可将XML数据转换为字典,简化XML解析过程,同时保留数据结构,便于操作。 反 -
python中pip的使用方法介绍
pip 是 Python 的默认包管理工具,随 Python 3.x 版本一同安装。它使得安装和管理 Python 包变得非常简单。本文将介绍 pip 的基本使用方法、常用 -
基于Python制作一个全自动微信清粉小工具
在当今社交软件中,微信是最常用的通讯工具之一。然而,随着时间的推移,我们的好友列表中可能会出现一些不再活跃的账号,也就是我 -
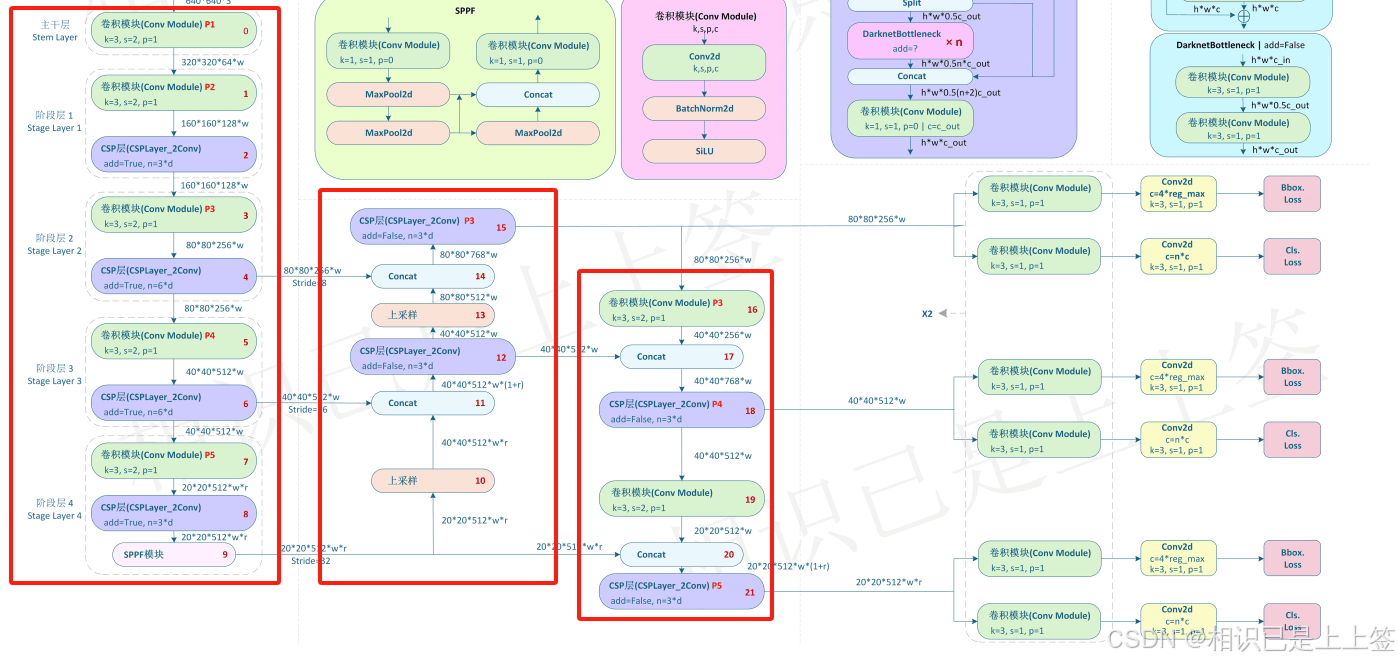
YOLOv8模型pytorch格式转为onnx格式的步骤介绍
一、YOLOv8的Pytorch网络结构 yolov8网络从1-21层与pt文件相对应是BackBone和Neck模块,22层是Head模块。 二、转ONNX步骤 2.1 yolov8官方 1 2 3 4 5 6 7 8 9 -

Python中addict库使用Dict的类
from addict import Dict这行代码导入了 Dict 类,它来自于 addict 模块。在这个上下文中,addict 是一个 Python 库,它提供了一个名为 Dict 的类,用于





-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

