
使用Python和Selenium构建一个自动化图像引擎

本篇指南将教你如何使用Python和Selenium库来构建一个自动化图像引擎,该引擎能够根据指定参数自动截取网页快照,并将生成的图片存储到云端。此工具还可以通过消息队列接收任务指令,非常
|
本篇指南将教你如何使用Python和Selenium库来构建一个自动化图像引擎,该引擎能够根据指定参数自动截取网页快照,并将生成的图片存储到云端。此工具还可以通过消息队列接收任务指令,非常适合需要批量处理网页截图的应用场景。 1. 准备环境确保你已经安装了Python和必要的库:
2. 创建配置文件创建一个简单的config.ini文件来存储你的OSS和Kafka设置:
3. 设置日志记录为程序添加基本的日志记录功能,以便于调试:
4. 初始化Selenium WebDriver初始化Chrome WebDriver,并设置窗口最大化:
5. 图像处理逻辑编写一个函数来处理每个Kafka消息,打开指定网页,等待页面加载完成,然后保存截图:
6. 启动Kafka消费者启动Kafka消费者,监听消息并调用处理函数:
总结通过上述简化步骤,你可以快速搭建一个基于Python和Selenium的图像引擎。该引擎能够从Kafka接收任务指令,访问指定网站,截取页面快照,并将截图上传到阿里云OSS。此版本去除了不必要的复杂性,专注于核心功能的实现。 |
您可能感兴趣的文章 :

-
Python图形化工具对比
Tkinter:Python内置的图形化库 Tkinter是Python的标准GUI库,它简单易用,适合初学者。Tkinter提供了创建窗口、按钮、文本框等常见控件的功能, -
使用Python和Selenium构建一个自动化图像引擎
本篇指南将教你如何使用Python和Selenium库来构建一个自动化图像引擎,该引擎能够根据指定参数自动截取网页快照,并将生成的图片存储到云 -
怎么创建Python虚拟环境venv
创建 Python 虚拟环境是一个很好的实践,可以帮助我们管理项目的依赖项,避免不同项目之间的冲突。以下是使用venv模块创建 Python 虚拟环境 -
Python实现Ollama的提示词生成与优化
1. 基础环境配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import requests import json from typing import List, Dict, Optional from dataclasses import dataclass @dataclas -
利用Python定位Span标签中文字
在开始之前,需要确保安装了必要的Python库。requests库用于发送HTTP请求,获取网页内容;BeautifulSoup库用于解析HTML文档,提取所需信息。 可 -
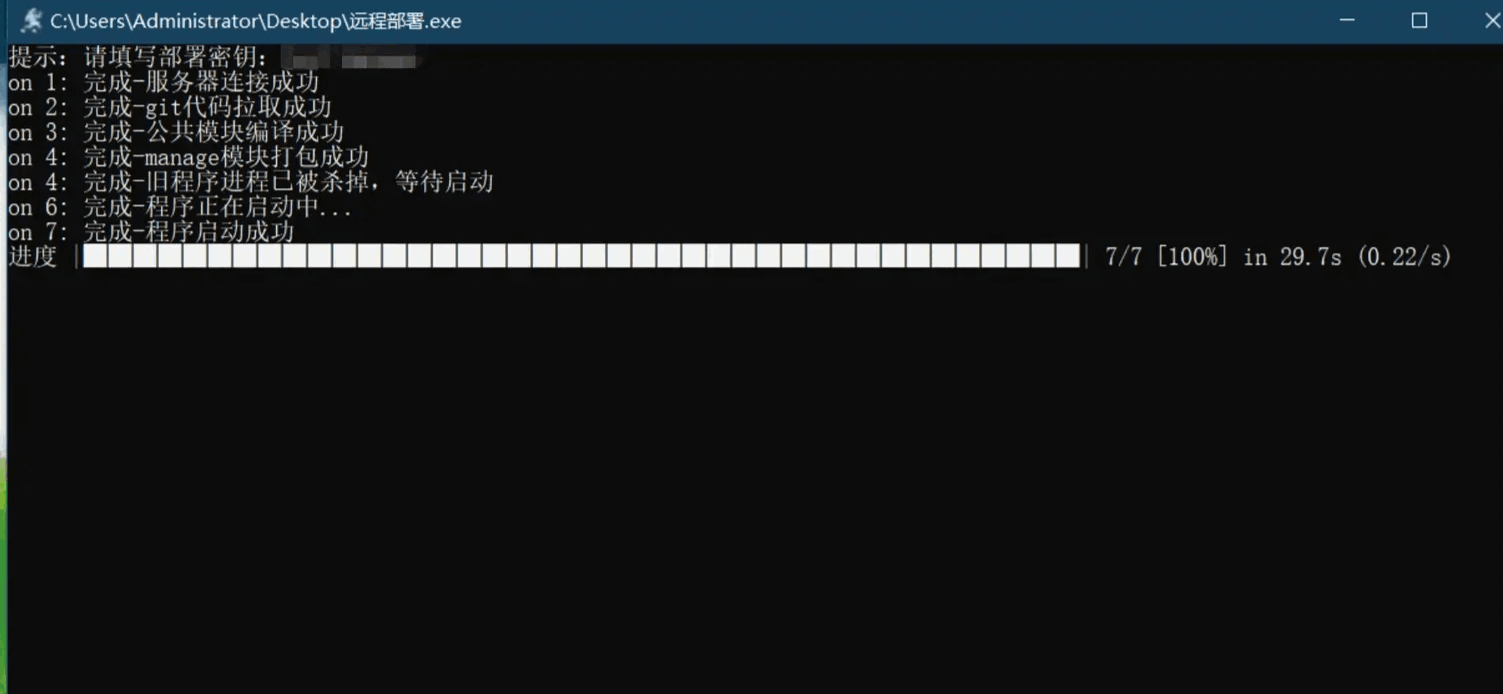
使用python编写一个自动化部署工具
效果 起因 现在springboot项目的自动化部署已经非常普遍,有用Jenkins的,有用git钩子函数的,有用docker的...等等。这段时间在玩python,想着用 -
Python中的下划线“_”们介绍
随便拿一份Python代码,几乎都可以看到很多_的身影。 在Python中,下划线(_)有多种用途和含义,具体取决于它们的位置和使用方式。在这 -
OpenCV-Python给图像去除水印多种方法
去除水印的过程与添加水印相反,它涉及到图像修复、颜色匹配和区域填充等技术。OpenCV-Python 提供了多种方法来处理不同类型的水印,包括 -
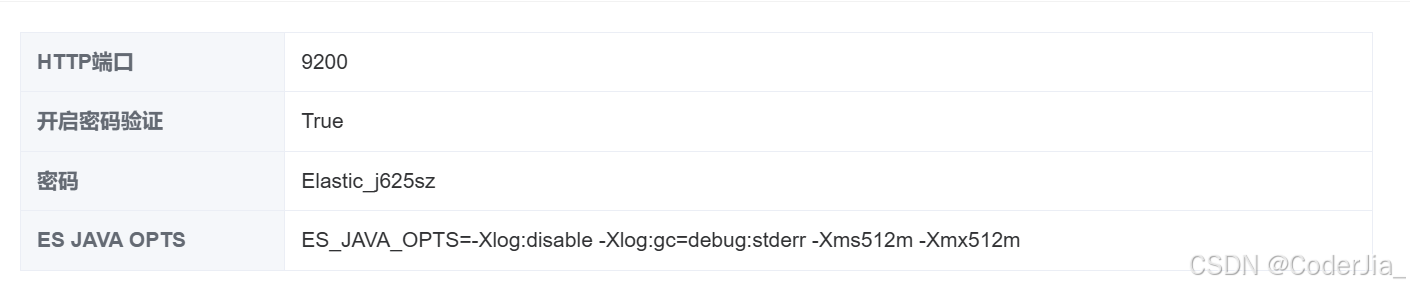
Python连接和操作Elasticsearch
一、服务器端配置 在开始之前,确保你的 Elasticsearch 服务已经在服务器上正确安装和配置。 以下是一些基本的配置步骤: 1. 修改 Elasticse



-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

