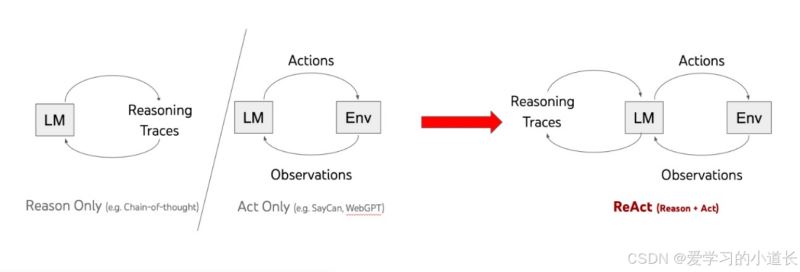
ReAct: Reasoning + Acting ,ReAct Prompt 由 few-shot task-solving trajectories 组成,包括人工编写的文本推理过程和动作,以及对动作的环境观察。
1. 范例
langchain version 0.3.7
|
1
2
3
4
5
6
7
8
9
10
11
|
$ pip show langchain
Name: langchain
Version: 0.3.7
Summary: Building applications with LLMs through composability
Home-page: https://github.com/langchain-ai/langchain
Author:
Author-email:
License: MIT
Location: /home/xjg/.conda/envs/langchain/lib/python3.10/site-packages
Requires: aiohttp, async-timeout, langchain-core, langchain-text-splitters, langsmith, numpy, pydantic, PyYAML, requests, SQLAlchemy, tenacity
Required-by: langchain-community
|
1.1 使用第三方工具
Google 搜索对接
第三方平台:https://serpapi.com
LangChain API 封装:SerpAPI
1.1.1 简单使用工具
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
from langchain_community.utilities import SerpAPIWrapper
import os
# 删除all_proxy环境变量
if 'all_proxy' in os.environ:
del os.environ['all_proxy']
# 删除ALL_PROXY环境变量
if 'ALL_PROXY' in os.environ:
del os.environ['ALL_PROXY']
os.environ["SERPAPI_API_KEY"] = "xxx"
params = {
"engine": "bing",
"gl": "us",
"hl": "en",
}
search = SerpAPIWrapper(params=params)
result = search.run("Obama's first name?")
print(result)
|
输出结果:
['In 1975, when Obama started high school in Hawaii, teacher Eric Kusunoki read the roll call and stumbled on Obama\'s first name. "Is Barack here?" he asked, pronouncing it BAR-rack .', "Barack Obama, the 44th president of the United States, was born on August 4, 1961, in Honolulu, Hawaii to Barack Obama, Sr. (1936–1982) (born in Oriang' Kogelo of Rachuonyo North District, Kenya) and Stanley Ann Dunham, known as Ann (1942–1995) (born in Wichita, Kansas, United States). Obama spent most of his childhood years in Honolulu, where his mother attended the University of Hawai?i at Mānoa", 'Barack Obama is named after his father, who was a Kenyan economist (called under the same name). He’s first real given name is “Barak”, also spelled Baraq (Not to be confused with Barack which is is a building or group of buildings …', 'Nevertheless, he was proud enough of his formal name that after he and Ann Dunham married in 1961, they named their son, Barack Hussein Obama II. As a youngster, the former president likely never...', 'https://www.britannica.com/biography/Barack-Obama', 'The name Barack means "one who is blessed" in Swahili. Obama was the first African-American U.S. president. Obama was the first president born outside of the contiguous United States. Obama was the eighth left-handed …', 'Barack Obama is the first Black president of the United States. Learn facts about him: his age, height, leadership legacy, quotes, family, and more.', 'Barack and Ann’s son, Barack Hussein Obama Jr., was born in Honolulu on August 4, 1961. Did you know? Not only was Obama the first African American president, he was also the first to be...', "President Obama's full name is Barack Hussein Obama. His full, birth name is Barack Hussein Obama, II. He was named after his father, Barack Hussein Obama, Sr., who …", 'When Barack Obama was elected president in 2008, he became the first African American to hold the office. The framers of the Constitution always hoped that our leadership would not be limited...']
1.1.2 使用第三方工具时ReAct
提示词 hwchase17/self-ask-with-search
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
from langchain_community.utilities import SerpAPIWrapper
from langchain.agents import create_self_ask_with_search_agent, AgentType,Tool,AgentExecutor
from langchain import hub
from langchain_openai import ChatOpenAI
import os
from dotenv import load_dotenv, find_dotenv
# 删除all_proxy环境变量
if 'all_proxy' in os.environ:
del os.environ['all_proxy']
# 删除ALL_PROXY环境变量
if 'ALL_PROXY' in os.environ:
del os.environ['ALL_PROXY']
_ = load_dotenv(find_dotenv())
os.environ["SERPAPI_API_KEY"] = "xxx"
chat_model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 实例化查询工具
search = SerpAPIWrapper()
tools = [
Tool(
name="Intermediate Answer",
func=search.run,
description="useful for when you need to ask with search",
)
]
prompt = hub.pull("hwchase17/self-ask-with-search")
self_ask_with_search = create_self_ask_with_search_agent(
chat_model,tools,prompt
)
agent_executor = AgentExecutor(agent=self_ask_with_search, tools=tools,verbose=True,handle_parsing_errors=True)
reponse = agent_executor.invoke({"input": "成都举办的大运会是第几届大运会?2023年大运会举办地在哪里?"})
print(reponse)
print(chat_model.invoke("成都举办的大运会是第几届大运会?").content)
print(chat_model.invoke("2023年大运会举办地在哪里?").content)
|
输出:
> Entering new AgentExecutor chain...
Could not parse output: Yes.
Follow up: 成都举办的大运会是由哪个组织举办的?
1. **成都举办的大运会是第几届大运会?**
- The 2023 Chengdu Universiade was the 31st Summer Universiade.
2. **2023年大运会举办地在哪里?**
- The 2023 Summer Universiade was held in Chengdu, China.
So the final answers are:
- 成都举办的大运会是第31届大运会。
- 2023年大运会举办地是成都,China。
如果你还有其他问题或需要进一步的澄清,请随时问我!
For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/OUTPUT_PARSING_FAILUREInvalid or incomplete response
> Finished chain.
{'input': '成都举办的大运会是第几届大运会?2023年大运会举办地在哪里?', 'output': '31届,成都,China'}
成都举办的世界大学生运动会是第31届大运会。该届大运会于2023年在中国成都举行。
2023年大运会(世界大学生运动会)将于2023年在中国成都举办。
1.2 使用langchain内置的工具
hwchase17/react
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
from langchain.agents import create_react_agent, AgentType,Tool,AgentExecutor
from langchain import hub
from langchain_community.agent_toolkits.load_tools import load_tools
from langchain.prompts import PromptTemplate
from dotenv import load_dotenv, find_dotenv
from langchain_openai import ChatOpenAI
import os
# 删除all_proxy环境变量
if 'all_proxy' in os.environ:
del os.environ['all_proxy']
# 删除ALL_PROXY环境变量
if 'ALL_PROXY' in os.environ:
del os.environ['ALL_PROXY']
_ = load_dotenv(find_dotenv())
os.environ["SERPAPI_API_KEY"] = "xxx"
chat_model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
prompt = hub.pull("hwchase17/react")
tools = load_tools(["serpapi", "llm-math"], llm=chat_model)
agent = create_react_agent(chat_model, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools,verbose=True)
reponse =agent_executor.invoke({"input": "谁是莱昂纳多·迪卡普里奥的女朋友?她现在年龄的0.43次方是多少?"})
print(reponse)
|
输出:
> Entering new AgentExecutor chain...
我需要先找到莱昂纳多·迪卡普里奥目前的女朋友是谁,然后获取她的年龄以计算年龄的0.43次方。
Action: Search
Action Input: "Leonardo DiCaprio girlfriend 2023"
Vittoria Ceretti我找到莱昂纳多·迪卡普里奥的女朋友是维多利亚·切雷提(Vittoria Ceretti)。接下来,我需要找到她的年龄以计算0.43次方。
Action: Search
Action Input: "Vittoria Ceretti age 2023"
About 25 years维多利亚·切雷提(Vittoria Ceretti)大约25岁。接下来,我将计算25的0.43次方。
Action: Calculator
Action Input: 25 ** 0.43
Answer: 3.991298452658078我现在知道最终答案
Final Answer: 莱昂纳多·迪卡普里奥的女朋友是维多利亚·切雷提,她的年龄0.43次方约为3.99。
> Finished chain.
{'input': '谁是莱昂纳多·迪卡普里奥的女朋友?她现在年龄的0.43次方是多少?', 'output': '莱昂纳多·迪卡普里奥的女朋友是维多利亚·切雷提,她的年龄0.43次方约为3.99。'}
1.3 使用自定义的工具
hwchase17/openai-functions-agent
1.3.1 简单使用
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
from langchain_openai import ChatOpenAI
from langchain.agents import tool,AgentExecutor,create_openai_functions_agent
from langchain import hub
import os
from dotenv import load_dotenv, find_dotenv
# 删除all_proxy环境变量
if 'all_proxy' in os.environ:
del os.environ['all_proxy']
# 删除ALL_PROXY环境变量
if 'ALL_PROXY' in os.environ:
del os.environ['ALL_PROXY']
_ = load_dotenv(find_dotenv())
chat_model = ChatOpenAI(model="gpt-4o-mini",temperature=0)
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
prompt = hub.pull("hwchase17/openai-functions-agent")
agent = create_openai_functions_agent(llm=chat_model, tools=tools, prompt=prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True,handle_parsing_errors=True)
agent_executor.invoke({"input": "单词“educati”中有多少个字母?"})
|
输出:
> Entering new AgentExecutor chain...
Invoking: `get_word_length` with `{'word': 'educati'}`
7单词“educati”中有7个字母。
> Finished chain.
1.3.1 带有记忆功能
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
from langchain_openai import ChatOpenAI
from langchain.agents import tool,AgentExecutor,create_openai_functions_agent
from langchain_core.prompts.chat import ChatPromptTemplate
from langchain.prompts import MessagesPlaceholder
from langchain.memory import ConversationBufferMemory
from langchain import hub
import os
from dotenv import load_dotenv, find_dotenv
# 删除all_proxy环境变量
if 'all_proxy' in os.environ:
del os.environ['all_proxy']
# 删除ALL_PROXY环境变量
if 'ALL_PROXY' in os.environ:
del os.environ['ALL_PROXY']
_ = load_dotenv(find_dotenv())
chat_model = ChatOpenAI(model="gpt-4o-mini",temperature=0)
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
prompt = ChatPromptTemplate.from_messages(
[
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent = create_openai_functions_agent(llm=chat_model, tools=tools, prompt=prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, memory=memory, verbose=True)
agent_executor.invoke({"input":"单词“educati”中有多少个字母?"})
agent_executor.invoke({"input":"那是一个真实的单词吗?"})
|
输出:
> Entering new AgentExecutor chain...
Invoking: `get_word_length` with `{'word': 'educati'}`
7
单词“educati”中有7个字母。
> Finished chain.
> Entering new AgentExecutor chain...
“educati”并不是一个标准的英语单词。它可能是“education”的一个变形或拼写错误。标准英语中的相关词是“education”,意为“教育”。
> Finished chain.
2. 参考
LangChain Hub https://smith.langchain.com/hub/
LangChain https://python.langchain.com/docs/introduction/
DevAGI开放平台 https://devcto.com/
|