
基于Python实现web网页内容爬取的方法

在日常学习和工作中,我们经常会遇到需要爬取网页内容的需求,今天就如何基于Python实现web网页内容爬取进行讲解。 1. 网页分析 用Chrome浏览器打开网页(https://car.yiche.com/)并进行分析。
|
在日常学习和工作中,我们经常会遇到需要爬取网页内容的需求,今天就如何基于Python实现web网页内容爬取进行讲解。 1. 网页分析用Chrome浏览器打开网页(https://car.yiche.com/)并进行分析。
F12键打开开发者视图,如下所示:
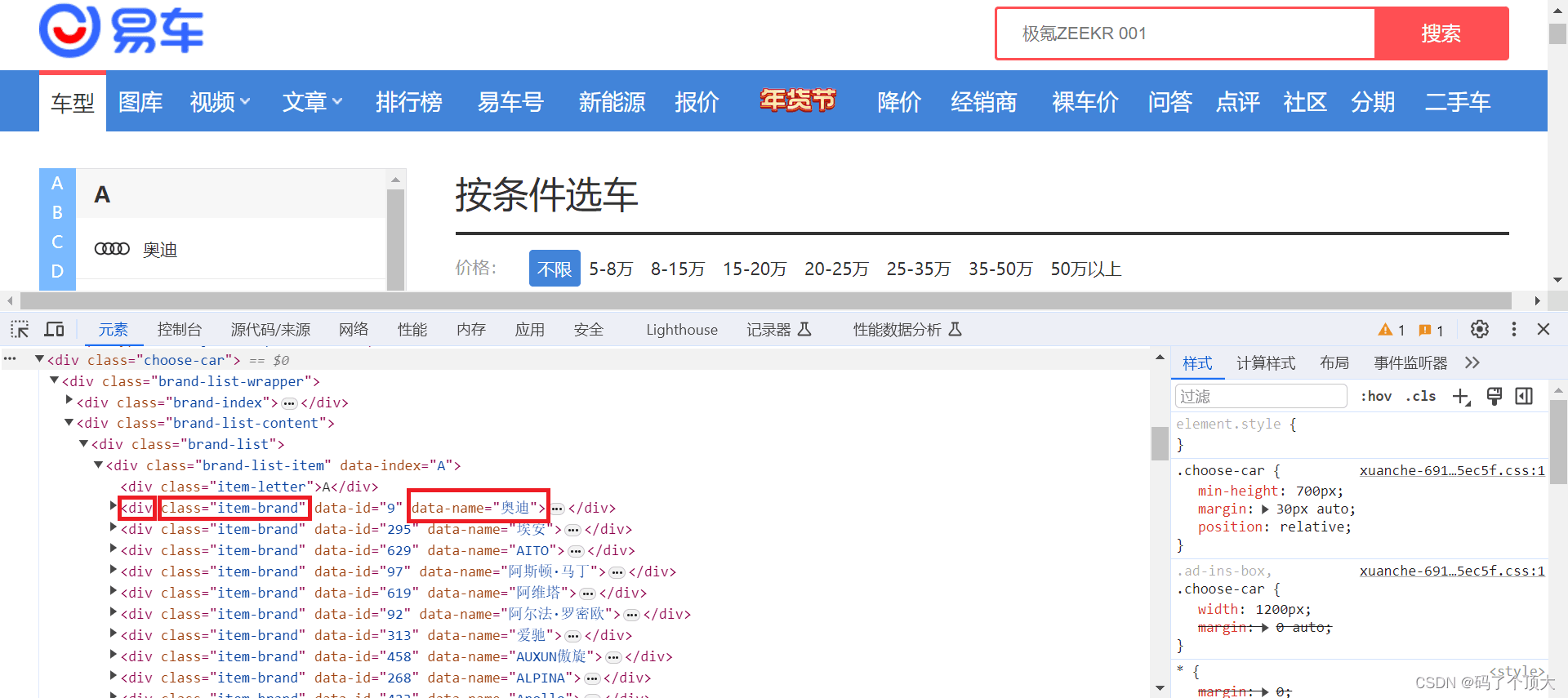
在网页页面上想要查看的页面内容处,点击 右键->检查(inspect) ,开发者模式中会自动选中对应的HTML代码。
分析发现车牌的名字在 name=“div”, attrs={“class”: “item-brand”}里面 2. 获取网页信息在Python中,我们可以使用 urllib.request 和 requests 这两个库来发送HTTP请求。这两个库都是用来处理URLs的,但是有一些区别。 2.1 使用默认的urllib.request库urllib.request是Python标准库中的一个模块,用于处理URLs的打开,读取和下载。它提供了一个简单的接口来发送HTTP请求,并可以处理响应数据。
2.2 使用requests库requests是一个第三方库,它提供了更简洁的API来发送HTTP请求,并处理响应数据。使用requests库可以更方便地发送各种类型的请求,如GET,POST等,并可以设置请求头,传递参数等。 首先在环境中安装 requests 库,命令如下:
输出如下:
2.3 urllib.request 和 requests库区别urllib.request 和 requests 这两个库的主要区别如下:
参考资料:python urllib.request和request的区别 3. 更改用户代理在使用Python进行网页爬取时,许多网站会通过检查HTTP请求头中的User-Agent字段来识别发出请求的客户端类型。设置用户代理(User-Agent)是为了模仿真实浏览器的请求,避免被网站识别为自动化工具而遭封锁,同时确保获取完整的网页内容,并遵守网站的访问规则。
4. BeautifulSoup库筛选数据BeautifulSoup库是一种HTML解析库,可以将HTML文档解析成Python对象,使得开发者可以方便地从HTML文档中提取数据。 首先需要安装 BeautifulSoup 库。
4.1 soup.find()和soup.find_all() 函数soup.find()和soup.find_all() 函数可以用来查找网页中特定的元素,区别在于:
soup.find()和soup.find_all() 函数的使用方式可参考:Python中bs4的soup.find()和soup.find_all()用法 参考资料
|
您可能感兴趣的文章 :

-
一文带你深入了解Python中的多进程编程
在 Python 中,多进程编程是一种提高程序运行效率的有效手段。相比于多线程编程,多进程编程可以充分利用多核 CPU 的优势,实现真正的并 -
使用Python实现屏幕录制与键盘监听功能
在Python中,我们可以借助多个强大的库来实现丰富的功能,比如屏幕录制和键盘监听。今天,我们将通过结合PIL(Python Imaging Library的分支 -
python中pathlib面向对象的文件系统路径
pathlib:面向对象的文件系统路径 pathlib官方介绍: Python3.4+内置的标准库,Object-oriented filesystem paths(面向对象的文件系统路径) 1. 使用示例 -
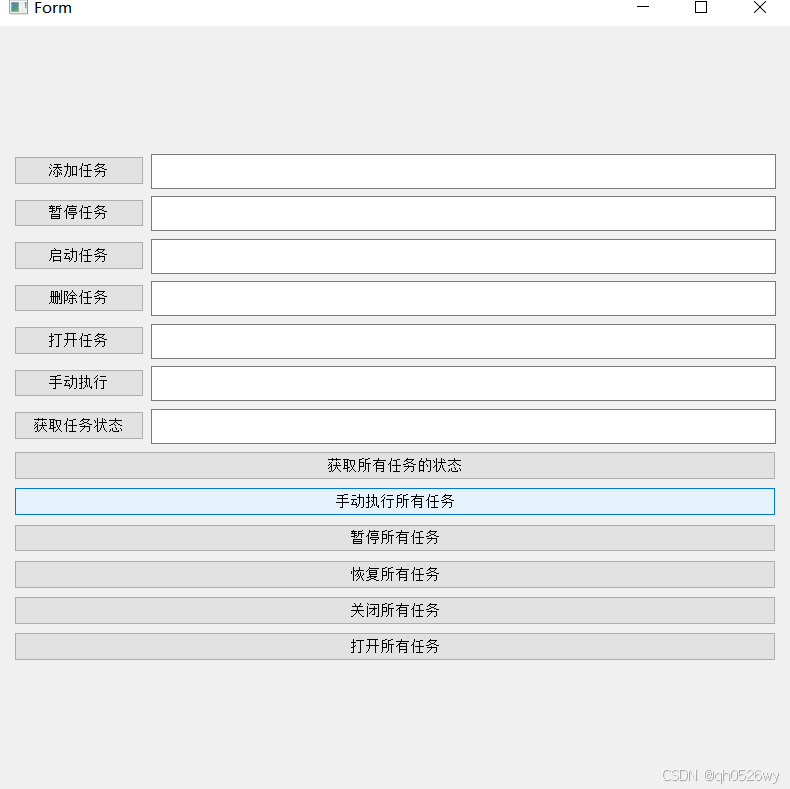
基于Python进行定时任务管理封装
效果图 主逻辑代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 -
Python中不可忽视的docstring妙用
在Python编程中,代码的可读性和可维护性至关重要。除了清晰的命名和结构良好的代码外,良好的文档字符串(docstring)也是确保代码易于 -
Python处理浮点数的实用技巧
四舍五入是一种常见的数学操作,它用于将数字舍入到指定的精度。Python 提供了多种方法来实现四舍五入操作,从基本的 round 函数到高级的 -
一文带你解锁Python文件匹配技巧
在日常的文件操作和数据处理中,文件匹配是一个非常常见的任务。Python 提供了丰富的库和工具来实现文件匹配,这些工具不仅功能强大, -
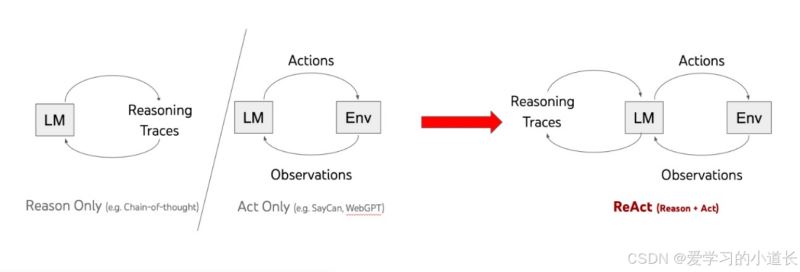
Python langchain ReAct使用范例介绍
ReAct: Reasoning + Acting ,ReAct Prompt 由 few-shot task-solving trajectories 组成,包括人工编写的文本推理过程和动作,以及对动作的环境观察。 1. 范例



-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

