
基于Python实现的通用小规模搜索引擎

1.1背景 《信息内容安全》网络信息内容获取技术课程项目设计 一个至少能支持10个以上网站的爬虫程序,且支持增量式数据采集;并至少采集10000个实际网页; 针对采集回来的网页内容, 能够实
1.1背景《信息内容安全》网络信息内容获取技术课程项目设计
1.2运行环境
安装依赖模块
1.3运行步骤安装配置ElasticSearch并启动
启动Web服务
数据的爬取与预处理
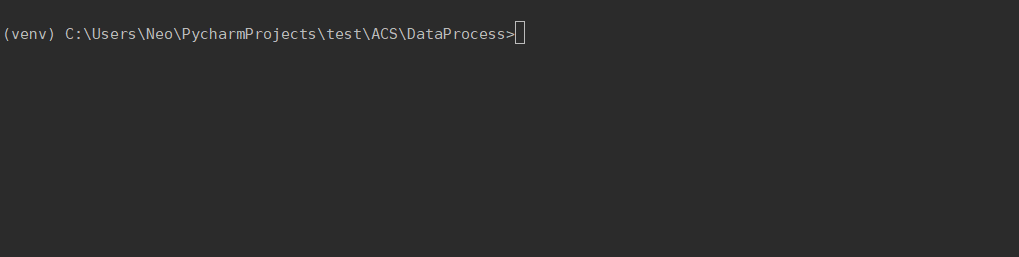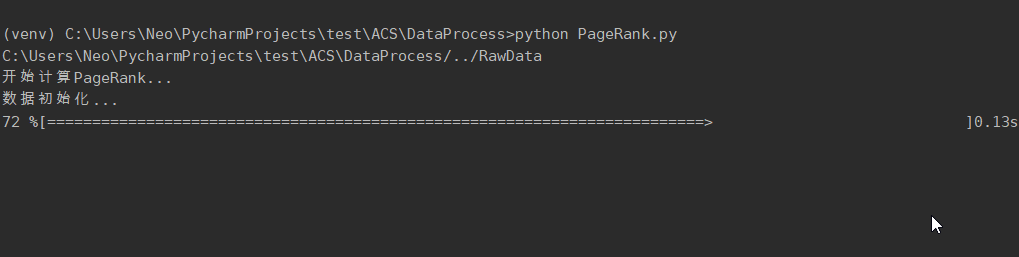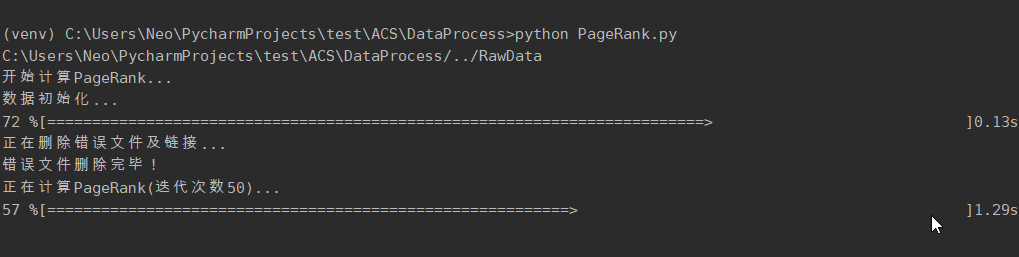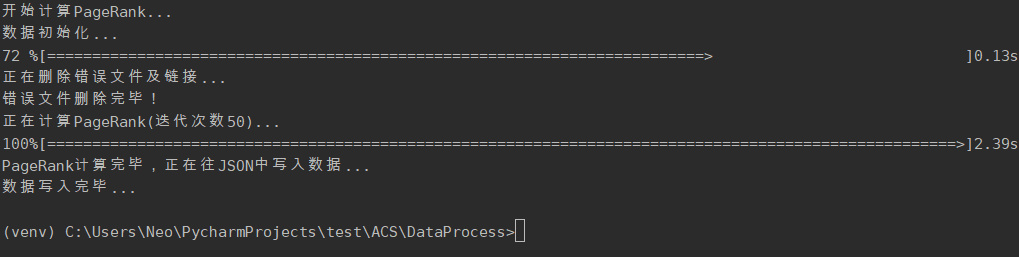
计算PageRank值
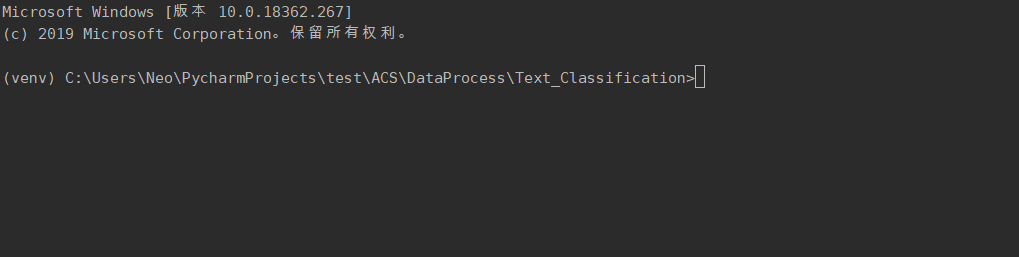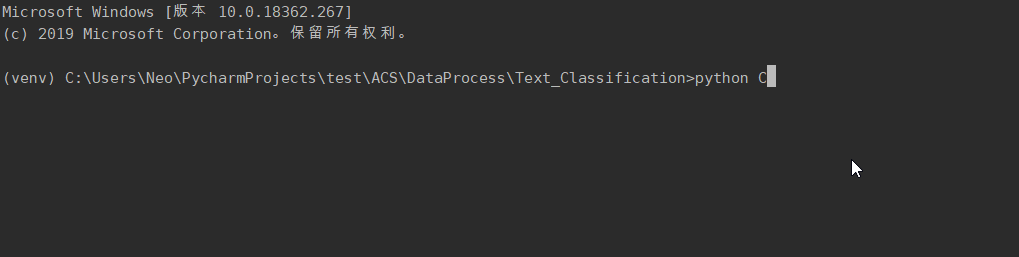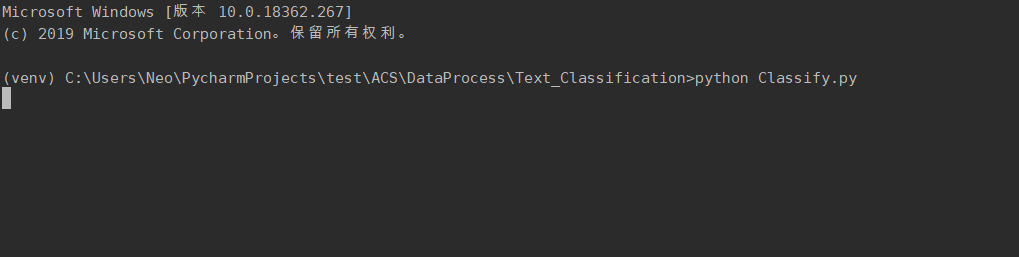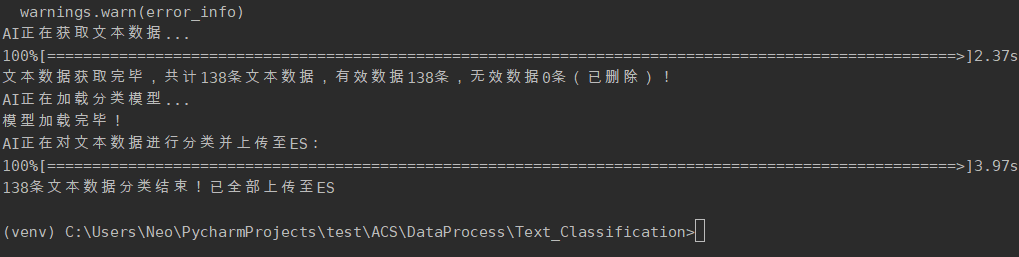
利用AI进行文本分类并上传至ES
2.需求分析2.1数据描述2.1.1 静态数据
2.1.2 动态数据
2.1.3索引数据字典页面(page)信息索引:
2.2. 数据采集种子 url 数据从 init_url 列表中选取,并按照顺序,依次以各个 url 为起点进行递归的数据采集 爬取数据的url需要限制在 restricted_url 列表里面 2.3功能需求2.3.1 数据爬取与预处理功能利用Python爬虫,执行以下步骤:
爬取网站如下信息,
2.3.2. 计算 PageRank 功能根据link计算爬取下来的每个网站的PageRank值,迭代次数为50次。解决pr值呈周期性变化的问题。将pr值作为网站重要程度的指标,并补充到网站信息中 2.3.3. AI 文本分类并提交到 ES 功能利用深度学习,分析每个页面的content的类别。将类别补充到网站信息中,同时删除网站信息中不再使用的link项,形成最终数据,并上传至ES,供用户交互功能调用。 2.3.4. 用户交互功能设计WebApp,用户通过浏览器访问页面。用户提交搜索信息后,判断合法性,不合法则返回ERROR界面提示用户。如果合法,则后端代码从本地 ES 中查询数据,处理后将结果分条显示到前端。同时通过限制单个ip每分钟的访问次数来简单防御用户恶意搜索。 2.4. 性能需求2.4.1. 数据精确度对数据精确度要求不高,主要数据为:
2.4.2. 时间特性
2.5. 运行需求2.5.1. 用户界面用户通过浏览器访问,有两个页面,一个是主页,只有简单的输入框提供用户搜索;另一个是一般界面,提供高级搜索功能,并显示搜索结果。 2.5.2. 主页
|输入框|接收用户输入的关键字|Logo图标下偏左 2.5.3. 搜索结果界面该界面分为三个部分,导航条、搜索结果、信息展示。这三个部分布局如下
导航条部分 以下控件从左向右依次(顺序可以任意)在导航条中排列
搜索结果部分 将搜索结果以list的形式展示出来,每个list item显示匹配的网站的如下数据
在list结尾,显示分页组件,使用户可以点击跳转,样式如下:
信息展示部分 展示一些必要信息,如:
2.5.4 软件接口
2.5.5. 故障处理各个功能模块如果出问题,会出现以下情况:
其中,后两个模块出问题会造成严重问题,如果重启不能解决问题的话,采用如下措施
2.6. 其他需求2.6.1. 可维护性
2.6.2. 可移植性
2.6.3. 数据完整性
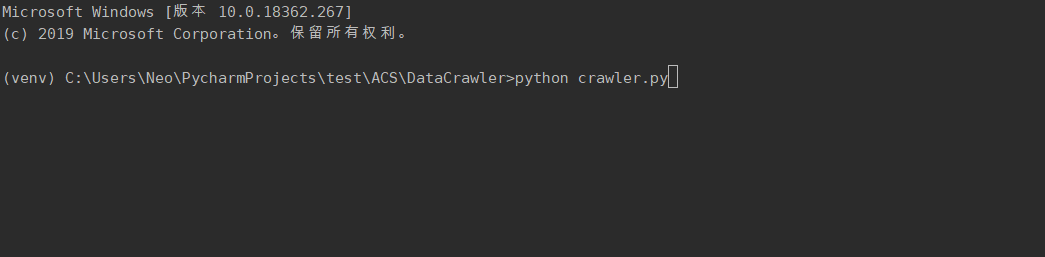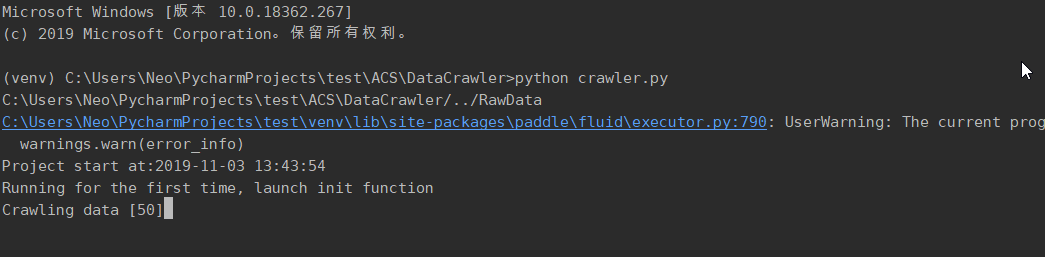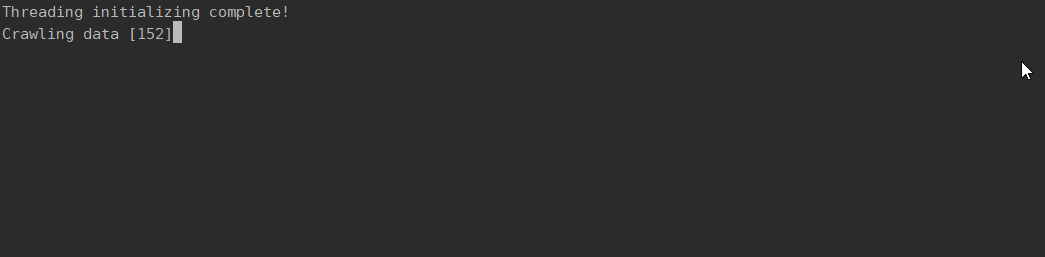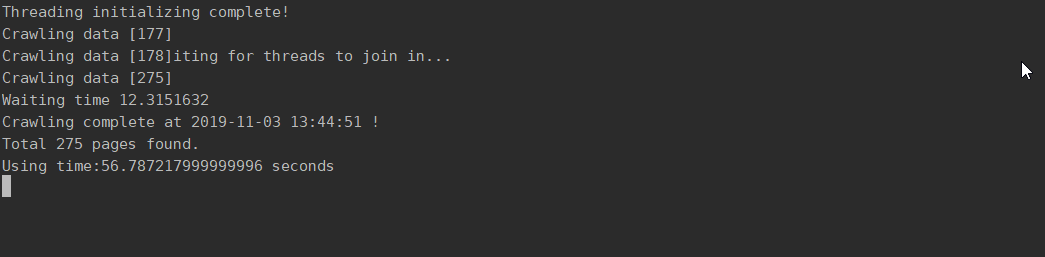
3.代码展示
4.系统展示
|

您可能感兴趣的文章 :

-
使用python实现无需验证码免登录12306抢票功能
就在刚刚我抢的票:2025年1月8日 上午9.00多 抢到了哈哈哈哈 其实还是有用的我是在 8:59:56运行程序的 上一篇帖子,我们已经了解了如何用 -
python字典根据key排序的实现
在 Python 中,字典是无序的,不支持直接按照键排序。但是可以通过以下方法实现字典按照键排序: 方法一:使用 sorted() 函数和字典的 it -
在Ubuntu上部署Flask应用的流程步骤
一、部署准备 在开始之前,请确保你具备以下条件: 一台运行 Ubuntu(如 Ubuntu 20.04 或 22.04)的服务器,具有 SSH 访问权限。 Python 应用程序 -
怎么使用celery进行异步处理和定时任务(django)
一、celery的作用 celery 是一个简单、灵活且可靠的分布式系统,用于处理大量消息,同时为操作提供一致的接口。它专注于实时操作,但支持 -
使用Python绘制蛇年春节祝福艺术图
1. 绘图的基本概念 在 Python 中,我们将使用以下方法和模块完成绘制任务: matplotlib.patches 模块: 提供了绘制基本几何图形的功能,例如圆 -

Python如何实现HTTP echo服务器
一个用来做测试的简单的 HTTP echo 服务器。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from ht -

python中_init_.py的作用
1. __init__.py 是个啥? __init__.py,顾名思义,这个文件名就透露出它是用来初始化的。在Python里,它主要用于标识一个目录是一个包(Package) -
Python调用JavaScript代码的几种方法
1. 使用PyExecJS执行JavaScript代码 PyExecJS是一个流行的Python库,它可以用来在Python中运行JavaScript代码。通过这个库,Python代码可以调用JS函数,



-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

