
Python中数据清洗与处理的常用方法

在数据处理与分析过程中,缺失值、重复值、异常值等问题是常见的挑战。 本文总结了多种数据清洗与处理方法: 缺失值处理包括删除缺失值、固定值填充、前后向填充以及删除缺失率高的列
|
在数据处理与分析过程中,缺失值、重复值、异常值等问题是常见的挑战。 本文总结了多种数据清洗与处理方法: 缺失值处理包括删除缺失值、固定值填充、前后向填充以及删除缺失率高的列; 重复值处理通过删除或标记重复项解决数据冗余问题; 异常值处理采用替换或标记方法控制数据质量; 数据类型转换确保数据格式符合分析需求,例如转换为整数或日期类型; 文本清洗包括去空格、字符替换及转换大小写等操作。 此外,还介绍了数据分组统计、数据分箱与标准化的应用。例如,分组统计可按列求均值,数据分箱能为连续变量赋予分类标签,而归一化则通过压缩数据范围提升模型表现。这些方法能有效提高数据质量与分析效率,是数据科学中不可或缺的能。 缺失值处理删除缺失值
用固定值填充缺失值
前向填充
后向填充
删除缺失率高的列
重复值处理删除重复值
标记重复值
异常值处理替换异常值
标记异常值
数据类型转换转换为整数类型
转换为日期类型
文本清洗去掉两端空格
替换特定字符
转换为小写
数据分组统计按列分组求均值
数据分箱按价格分箱
数据标准化归一化处理
|
您可能感兴趣的文章 :

-

使用Python实现操作mongodb的介绍
一、示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 -
使用Python合并Excel单元格指定行列或单元格范围
合并 Excel 单元格是 Excel 数据处理和表格设计中的一项常用操作。例如,在制作表格标题时,经常会将多个单元格合并,使标题能够跨列显示 -
Python中数据清洗与处理的常用方法
在数据处理与分析过程中,缺失值、重复值、异常值等问题是常见的挑战。 本文总结了多种数据清洗与处理方法: 缺失值处理包括删除缺失 -
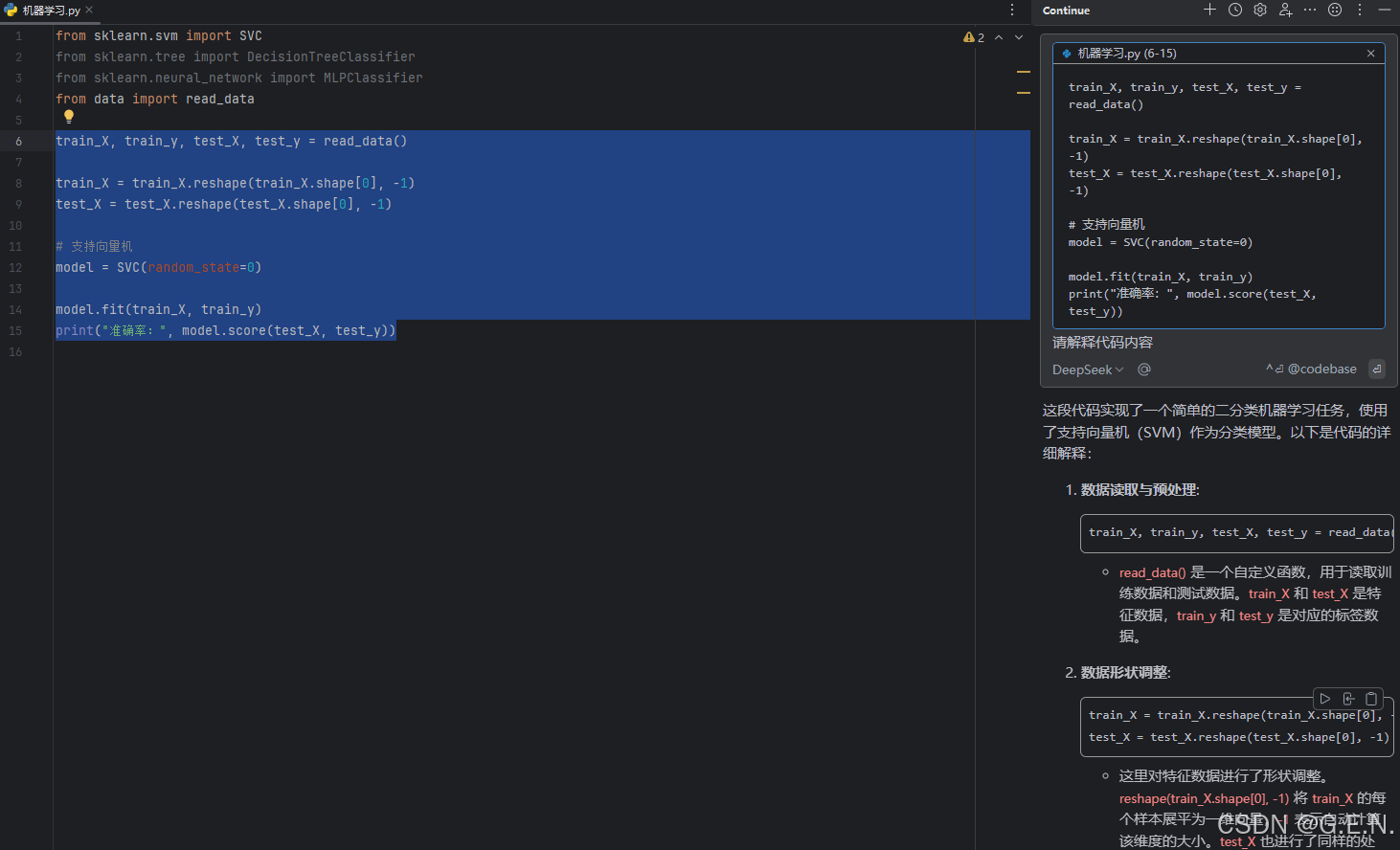
PyCharm接入DeepSeek实现AI编程的操作流程
DeepSeek 是一家专注于人工智能技术研发的公司,致力于开发高性能、低成本的 AI 模型。DeepSeek-V3 是 DeepSeek 公司推出的最新一代 AI 模型。其 -
使用Python实现高效的端口扫描器
1. 端口扫描的基本原理 端口扫描的基本原理是向目标主机的指定端口发送数据包,并监听是否有来自该端口的响应。根据响应的不同,可以 -
Python判断for循环最后一次的6种方法
1.使用enumerate()和len()来判断for循环最后一次迭代 一种常见的方法是使用enumerate()函数来获取迭代的索引和值,并通过比较索引和可迭代对象 -
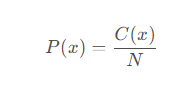
Python中使用defaultdict和Counter的方法
在Python编程中,字典(dict)是最常用的数据结构之一,广泛应用于数据存储、检索和操作。然而,随着数据规模的增大和复杂性的提升,传 -
从基础到进阶带你玩转Python中的异常处理
在编程过程中,我们经常会遇到各种运行时错误,比如除零错误、文件未找到错误等。为了处理这些错误,Python提供了强大的异常处理机制




-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

