
Python从零开始训练AI模型的教程

人工智能(AI)是当今科技领域的热门话题之一。在过去的几年里,AI技术在各个领域都取得了重大的突破和应用,例如图像识别、语音识别、自然语言处理等。如果你对AI感兴趣,并且想要亲
|
人工智能(AI)是当今科技领域的热门话题之一。在过去的几年里,AI技术在各个领域都取得了重大的突破和应用,例如图像识别、语音识别、自然语言处理等。如果你对AI感兴趣,并且想要亲自动手训练自己的AI模型,那么本篇博客将为你提供一些详细的指导。 思维导图以下是使用Mermaid代码绘制的思维导图,展示了从零训练自己的AI模型的主要步骤和技术:
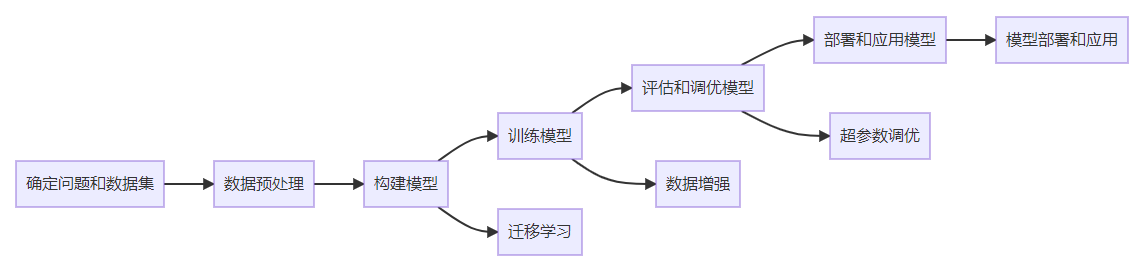
以上思维导图清晰地展示了从问题和数据集确定到模型部署和应用的整个过程。通过按照思维导图的指引,你可以一步步地使用Python训练自己的AI模型,并将其用于实际问题的解决。 确定问题和数据集首先,你需要明确你要解决的问题,并找到合适的数据集来训练你的模型。例如,你可以选择图像分类、情感分析、文本生成等不同的任务。在选择数据集时,要确保数据集的质量和适用性,以便训练出高质量的模型。 数据预处理在开始训练模型之前,通常需要对数据进行预处理。这包括数据清洗、特征提取和数据转换等步骤。例如,对于图像分类任务,你可能需要将图像转换为数字矩阵,并对图像进行缩放和标准化处理。
构建模型接下来,你需要选择适合你问题的模型架构,并使用Python构建模型。Python中有许多流行的机器学习库,例如TensorFlow、PyTorch和Scikit-learn,可以帮助你构建和训练模型。
训练模型一旦模型构建完成,你就可以使用数据集来训练模型了。在训练过程中,你需要定义损失函数和优化算法,并选择适当的训练参数。通常,你需要将数据集分为训练集和验证集,用于评估模型的性能。
评估和调优模型训练完成后,你需要评估模型的性能,并进行模型的调优。通过分析模型在验证集上的表现,你可以调整模型的参数、增加数据量或者尝试其他算法,以获得更好的性能。
部署和应用模型最后,一旦你对模型的性能满意,你可以将其部署到实际应用中并使用它来解决实际问题。例如,你可以将训练好的图像分类模型部署到一个Web应用程序中,用于自动识别上传的图像。 数据增强在训练模型之前,你可以虑使用数据增强来提升模型的泛化能力。数据增强是一种通过对原始数据进行随机变换和扩充来更多训练样本的技术。这可以帮助型更好地适不同的场景和变。
迁移学习迁移学习是一种利用已经在大型数据集上预训练好的模型来解决新问题的技术。通过复用已训练模型的一部分或全部权重,加快模型训练的速度并提高模型的性能。
超参数调优在训练模型的过程中,你可能需要调整模型的超参数以得更好的性能。超参数是指在训练过程中会被模型学习的参数,例如学习率、批大小、代次数等。通过尝试不同的超参数组合,可以找到最佳的模型配置。
模型部署和应用一旦你对模型的性能和效果满意,你可以将部署到实际应用中并应用于实际问题。根据你的求,你可以选择将模型封装为API、嵌入到移动应用程序中或者部署到云服务器上。
总结本篇博客介绍了如何使用Python从零训练自己的AI模型。以下是本篇博客的主要内容总结: 确定问题和数据集:明确要解决的问题,并选择合适的数据集。 此外,还介绍了一些进阶技术,包括数据增强、迁移学习和超参数调优,以提升模型的性能和泛化能力。最后,展示了如何将模型封装为API并部署到实际应用中。 希望本篇博客对你在AI模型训练的学习和实践中有所帮助!祝你成功! |
您可能感兴趣的文章 :

-
Python实现文件下载、Cookie以及重定向的方法
本文主要介绍了如何使用 Python 的requests模块进行网络请求操作,涵盖了从文件下载、Cookie 处理到重定向与历史请求等多个方面。通过详细的 -
Python使用execute_script模拟鼠标滚动、鼠标点击
我们在写selenium获取网络信息的时候,有时候我们会受到对方浏览器js的监控,对方通过分析用户行为模式,如点击、滚动、停留时间等,网 -
Matplotlab显示OpenCV读取到的图像
一. 确认图像的数组类型 在使用 OpenCV 的cv2.imread()函数读取图像时,第二个参数(标志)决定了图像的读取方式。具体来说,0、1和-1分别对 -
python无需验证码免登录12306抢票
就在刚刚我抢的票:2025年1月8日 上午9.00多 抢到了哈哈哈哈 其实还是有用的我是在 8:59:56运行程序的 配置selenium自动化的帖子链接:https -
python怎么计算超出int范围内的书
在Python中,整型(int)可以根据需要动态扩展其大小,不会因为数值超出某个固定范围而造成溢出。尽管如此,处理非常大的整数或在某些 -

使用Python实现操作mongodb的介绍
一、示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 -
使用Python合并Excel单元格指定行列或单元格范围
合并 Excel 单元格是 Excel 数据处理和表格设计中的一项常用操作。例如,在制作表格标题时,经常会将多个单元格合并,使标题能够跨列显示 -
Python中数据清洗与处理的常用方法
在数据处理与分析过程中,缺失值、重复值、异常值等问题是常见的挑战。 本文总结了多种数据清洗与处理方法: 缺失值处理包括删除缺失




-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

