
Python实现将PDF文件拆分任意页数介绍

PyMuPDF,简称fitz,是一个轻量级的Python库,它基于MuPDF的C++库,提供了丰富的功能,包括但不限于PDF的读取、编辑、转换和渲染。Fitz作为PyMuPDF的子模块,简化和封装了PyMuPDF的功能,使得在Pyt
|
PyMuPDF,简称fitz,是一个轻量级的Python库,它基于MuPDF的C++库,提供了丰富的功能,包括但不限于PDF的读取、编辑、转换和渲染。Fitz作为PyMuPDF的子模块,简化和封装了PyMuPDF的功能,使得在Python中处理PDF文件更加简单。 二、安装PyMuPDF(包含fitz模块)可以通过Python的包管理器pip来安装。 在命令行工具中输入以下命令:
这将从Python包索引下载并安装PyMuPDF及其依赖项。 或者
三、基本功能1、打开PDF文件: 使用fitz.open()函数可以打开一个PDF文件,并返回一个表示该文件的对象。例如:
2、获取页面数量: 通过page_count属性可以获取PDF文件的总页数。例如:
3、提取文本: 使用get_text()方法可以提取当前页面的所有文本。例如:
此外,还可以遍历文档中的每一页,提取每一页的文本。 4、保存修改后的PDF: 使用save()方法可以保存对PDF文件所做的更改。例如:
其他功能:
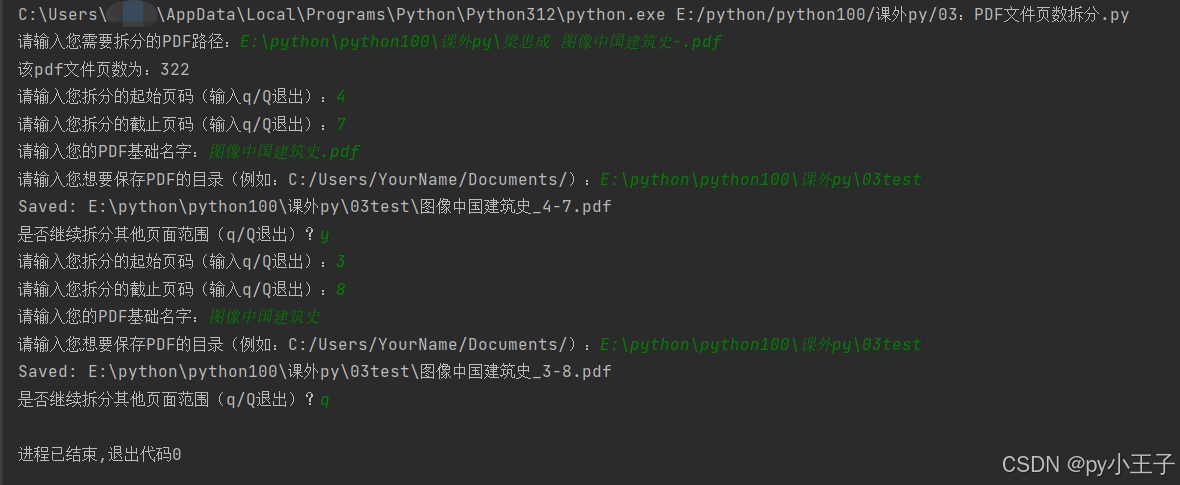
四、应用场景PyMuPDF(fitz)适用于需要处理PDF文件的各种场景,如文本提取、页面操作、PDF合并与分割等。它以其快速、高效和易于使用而著称,是处理PDF文件的理想选择。 例如:PDF文件拆分任意页数.py
|

您可能感兴趣的文章 :

-
Python+PyQt手搓一个文件浏览器
一、效果展示 二、界面设计 该界面通过Qt Designer设计 ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 -
Python实现将PDF文件拆分任意页数介绍
PyMuPDF,简称fitz,是一个轻量级的Python库,它基于MuPDF的C++库,提供了丰富的功能,包括但不限于PDF的读取、编辑、转换和渲染。Fitz作为Py -
20个实用的Python Excel自动化脚本介绍
在数据处理和分析的过程中,Excel文件是我们日常工作中常见的格式。通过Python,我们可以实现对Excel文件的各种自动化操作,提高工作效率 -
使用Python IDLE进行Debug调试的图文介绍
1.首先以我的Python版本为例为大家讲解,我的版本是Python 3.7,版本问题对使用情况影响不大。 2.接着我们可以通过新建文件夹来输入我们的 -
Python给Excel写入数据的四种方法介绍
Python 在数据处理领域应用广泛,其中与 Excel 文件的交互是常见需求之一。 本文将介绍四种使用 Python 给Excel 文件写入数据的方法,并结合生 -
用Python编写一个MP3分割工具
最终效果图 代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 -
Python如何生成requirements.txt
在 Python 项目中,requirements.txt文件通常用于列出项目依赖的库及其版本号。这样可以方便地在其他环境中安装相同的依赖。 以下是生成req -
10个Python Excel自动化脚本分享介绍
在数据处理和分析的过程中,Excel文件是我们日常工作中常见的格式。通过Python,我们可以实现对Excel文件的各种自动化操作,提高工作效率



-
python批量下载抖音视频
2019-06-18
-
利用Pyecharts可视化微信好友的方法
2019-07-04
-
python爬取豆瓣电影TOP250数据
2021-05-23
-
基于tensorflow权重文件的解读
2021-05-27
-
解决Python字典查找报Keyerror的问题
2021-05-27

