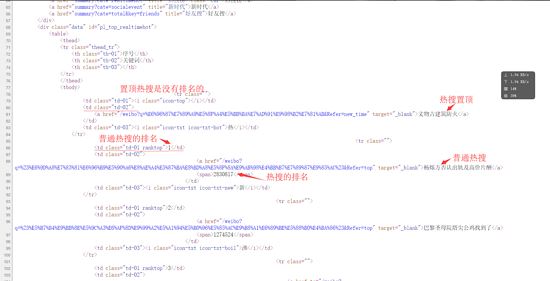
本篇文章介绍Python网络爬虫之爬取微博热搜的方法。 微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url= https://s.weibo.com/top/summary?Refer=top_hottopnav=1wvr=6 1.分析网页的源代码:右键--查看网页源代码. 从网页代码中可以获取到信息 (1
|
|







2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27