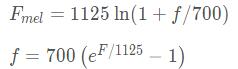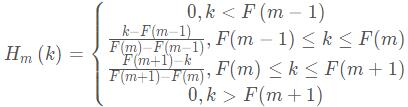import wave
import numpy as np
import math
import matplotlib.pyplot as plt
from scipy.fftpack import dct
def read(data_path):
'''读取语音信号
'''
wavepath = data_path
f = wave.open(wavepath,'rb')
params = f.getparams()
nchannels,sampwidth,framerate,nframes = params[:4] #声道数、量化位数、采样频率、采样点数
str_data = f.readframes(nframes) #读取音频,字符串格式
f.close()
wavedata = np.fromstring(str_data,dtype = np.short) #将字符串转化为浮点型数据
wavedata = wavedata * 1.0 / (max(abs(wavedata))) #wave幅值归一化
return wavedata,nframes,framerate
def enframe(data,win,inc):
'''对语音数据进行分帧处理
input:data(一维array):语音信号
wlen(int):滑动窗长
inc(int):窗口每次移动的长度
output:f(二维array)每次滑动窗内的数据组成的二维array
'''
nx = len(data) #语音信号的长度
try:
nwin = len(win)
except Exception as err:
nwin = 1
if nwin == 1:
wlen = win
else:
wlen = nwin
nf = int(np.fix((nx - wlen) / inc) + 1) #窗口移动的次数
f = np.zeros((nf,wlen)) #初始化二维数组
indf = [inc * j for j in range(nf)]
indf = (np.mat(indf)).T
inds = np.mat(range(wlen))
indf_tile = np.tile(indf,wlen)
inds_tile = np.tile(inds,(nf,1))
mix_tile = indf_tile + inds_tile
f = np.zeros((nf,wlen))
for i in range(nf):
for j in range(wlen):
f[i,j] = data[mix_tile[i,j]]
return f
def point_check(wavedata,win,inc):
'''语音信号端点检测
input:wavedata(一维array):原始语音信号
output:StartPoint(int):起始端点
EndPoint(int):终止端点
'''
#1.计算短时过零率
FrameTemp1 = enframe(wavedata[0:-1],win,inc)
FrameTemp2 = enframe(wavedata[1:],win,inc)
signs = np.sign(np.multiply(FrameTemp1,FrameTemp2)) # 计算每一位与其相邻的数据是否异号,异号则过零
signs = list(map(lambda x:[[i,0] [i>0] for i in x],signs))
signs = list(map(lambda x:[[i,1] [i<0] for i in x], signs))
diffs = np.sign(abs(FrameTemp1 - FrameTemp2)-0.01)
diffs = list(map(lambda x:[[i,0] [i<0] for i in x], diffs))
zcr = list((np.multiply(signs, diffs)).sum(axis = 1))
#2.计算短时能量
amp = list((abs(enframe(wavedata,win,inc))).sum(axis = 1))
# # 设置门限
# print('设置门限')
ZcrLow = max([round(np.mean(zcr)*0.1),3])#过零率低门限
ZcrHigh = max([round(max(zcr)*0.1),5])#过零率高门限
AmpLow = min([min(amp)*10,np.mean(amp)*0.2,max(amp)*0.1])#能量低门限
AmpHigh = max([min(amp)*10,np.mean(amp)*0.2,max(amp)*0.1])#能量高门限
# 端点检测
MaxSilence = 8 #最长语音间隙时间
MinAudio = 16 #最短语音时间
Status = 0 #状态0:静音段,1:过渡段,2:语音段,3:结束段
HoldTime = 0 #语音持续时间
SilenceTime = 0 #语音间隙时间
print('开始端点检测')
StartPoint = 0
for n in range(len(zcr)):
if Status ==0 or Status == 1:
if amp[n] > AmpHigh or zcr[n] > ZcrHigh:
StartPoint = n - HoldTime
Status = 2
HoldTime = HoldTime + 1
SilenceTime = 0
elif amp[n] > AmpLow or zcr[n] > ZcrLow:
Status = 1
HoldTime = HoldTime + 1
else:
Status = 0
HoldTime = 0
elif Status == 2:
if amp[n] > AmpLow or zcr[n] > ZcrLow:
HoldTime = HoldTime + 1
else:
SilenceTime = SilenceTime + 1
if SilenceTime < MaxSilence:
HoldTime = HoldTime + 1
elif (HoldTime - SilenceTime) < MinAudio:
Status = 0
HoldTime = 0
SilenceTime = 0
else:
Status = 3
elif Status == 3:
break
if Status == 3:
break
HoldTime = HoldTime - SilenceTime
EndPoint = StartPoint + HoldTime
return FrameTemp1[StartPoint:EndPoint]
def mfcc(FrameK,framerate,win):
'''提取mfcc参数
input:FrameK(二维array):二维分帧语音信号
framerate:语音采样频率
win:分帧窗长(FFT点数)
output:
'''
#mel滤波器
mel_bank,w2 = mel_filter(24,win,framerate,0,0.5)
FrameK = FrameK.T
#计算功率谱
S = abs(np.fft.fft(FrameK,axis = 0)) ** 2
#将功率谱通过滤波器
P = np.dot(mel_bank,S[0:w2,:])
#取对数
logP = np.log(P)
#计算DCT系数
# rDCT = 12
# cDCT = 24
# dctcoef = []
# for i in range(1,rDCT+1):
# tmp = [np.cos((2*j+1)*i*math.pi*1.0/(2.0*cDCT)) for j in range(cDCT)]
# dctcoef.append(tmp)
# #取对数后做余弦变换
# D = np.dot(dctcoef,logP)
num_ceps = 12
D = dct(logP,type = 2,axis = 0,norm = 'ortho')[1:(num_ceps+1),:]
return S,mel_bank,P,logP,D
def mel_filter(M,N,fs,l,h):
'''mel滤波器
input:M(int):滤波器个数
N(int):FFT点数
fs(int):采样频率
l(float):低频系数
h(float):高频系数
output:melbank(二维array):mel滤波器
'''
fl = fs * l #滤波器范围的最低频率
fh = fs * h #滤波器范围的最高频率
bl = 1125 * np.log(1 + fl / 700) #将频率转换为mel频率
bh = 1125 * np.log(1 + fh /700)
B = bh - bl #频带宽度
y = np.linspace(0,B,M+2) #将mel刻度等间距
print('mel间隔',y)
Fb = 700 * (np.exp(y / 1125) - 1) #将mel变为HZ
print(Fb)
w2 = int(N / 2 + 1)
df = fs / N
freq = [] #采样频率值
for n in range(0,w2):
freqs = int(n * df)
freq.append(freqs)
melbank = np.zeros((M,w2))
print(freq)
for k in range(1,M+1):
f1 = Fb[k - 1]
f2 = Fb[k + 1]
f0 = Fb[k]
n1 = np.floor(f1/df)
n2 = np.floor(f2/df)
n0 = np.floor(f0/df)
for i in range(1,w2):
if i >= n1 and i <= n0:
melbank[k-1,i] = (i-n1)/(n0-n1)
if i >= n0 and i <= n2:
melbank[k-1,i] = (n2-i)/(n2-n0)
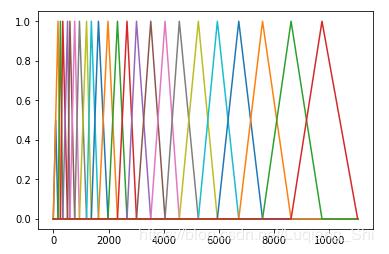
plt.plot(freq,melbank[k-1,:])
plt.show()
return melbank,w2
if __name__ == '__main__':
data_path = 'audio_data.wav'
win = 256
inc = 80
wavedata,nframes,framerate = read(data_path)
FrameK = point_check(wavedata,win,inc)
S,mel_bank,P,logP,D = mfcc(FrameK,framerate,win)
|