#创建:2016/01/26
#文件:BarCodeIdentification.py
#作者:moverzp
#功能:识别条形码
import sys
import cv2
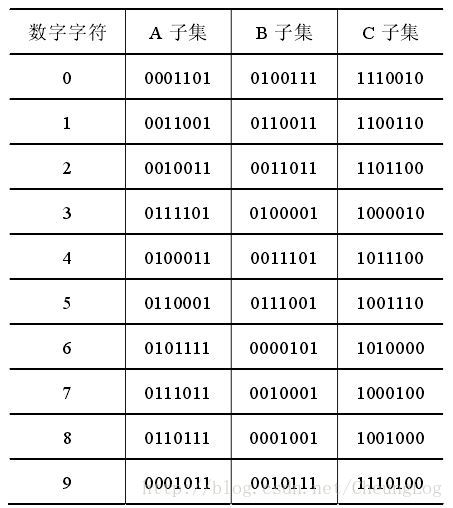
DECODING_TABLE = {
'0001101': 0, '0100111': 0, '1110010': 0,
'0011001': 1, '0110011': 1, '1100110': 1,
'0010011': 2, '0011011': 2, '1101100': 2,
'0111101': 3, '0100001': 3, '1000010': 3,
'0100011': 4, '0011101': 4, '1011100': 4,
'0110001': 5, '0111001': 5, '1001110': 5,
'0101111': 6, '0000101': 6, '1010000': 6,
'0111011': 7, '0010001': 7, '1000100': 7,
'0110111': 8, '0001001': 8, '1001000': 8,
'0001011': 9, '0010111': 9, '1110100': 9,
}
EDGE_TABLE = {
2:{2:6,3:0,4:4,5:3},
3:{2:9,3:'33',4:'34',5:5},
4:{2:9,3:'43',4:'44',5:5},
5:{2:6,3:0,4:4,5:3},
}
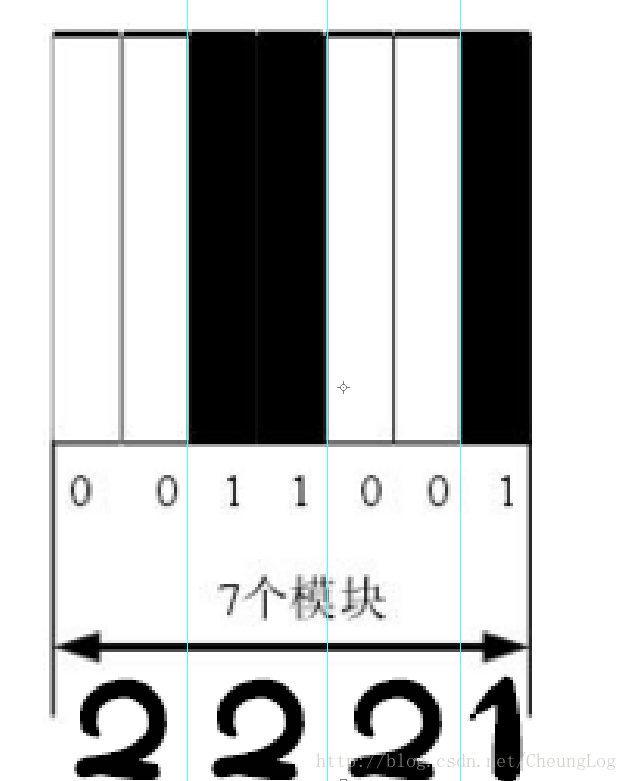
INDEX_IN_WIDTH = (0, 4, 8, 12, 16, 20, 24, 33, 37, 41, 45, 49, 53)
def get_bar_space_width(img):
row = img.shape[0] *1/2
currentPix = -1
lastPix = -1
pos = 0
width = []
for i in range(img.shape[1]):#遍历一整行
currentPix = img[row][i]
if currentPix != lastPix:
if lastPix == -1:
lastPix = currentPix
pos = i
else:
width.append( i - pos )
pos = i
lastPix = currentPix
return width
def divide(t, l):
if float(t) / l < 0.357:
return 2
elif float(t) / l < 0.500:
return 3
elif float(t) / l < 0.643:
return 4
else:
return 5
def cal_similar_edge(data):
similarEdge = []
#先判断起始符
limit = float(data[1] + data[2] + data[3] ) / 3 * 1.5
if data[1] >= limit or data[2] >= limit or data[3] >= limit:
return -1#宽度提取失败
index = 4
while index < 54:
#跳过分隔符区间
if index==28 or index==29 or index==30 or index==31 or index==32:
index +=1
continue
#字符检测
T1 = data[index] + data[index+1]
T2 = data[index+1] + data[index+2]
L = data[index] + data[index+1] + data[index+2] + data[index+3]
similarEdge.append( divide(T1, L) )
similarEdge.append( divide(T2, L) )
index += 4
return similarEdge
def decode_similar_edge(edge):
barCode = [6]#第一个字符一定是6,中国区
for i in range (0, 24, 2):#每个字符两个相似边,共12个字符
barCode.append( EDGE_TABLE[edge[i]][edge[i+1]] )
return barCode
def decode_sharp(barCode, barSpaceWidth):
for i in range(0, 13):
if barCode[i] == '44':
index = INDEX_IN_WIDTH[i]
c3 = barSpaceWidth[index+2]
c4 = barSpaceWidth[index+3]
if c3 > c4:
barCode[i] = 1
else:
barCode[i] = 7
elif barCode[i] == '33':
index = INDEX_IN_WIDTH[i]
c1 = barSpaceWidth[index]
c2 = barSpaceWidth[index+1]
if c1 > c2:
barCode[i] = 2
else:
barCode[i] = 8
elif barCode[i] == '34':
index = INDEX_IN_WIDTH[i]
c1 = barSpaceWidth[index]
c2 = barSpaceWidth[index+1]
if c1 > c2:
barCode[i] = 7
else:
barCode[i] = 1
elif barCode[i] == '43':
index = INDEX_IN_WIDTH[i]
c2 = barSpaceWidth[index+1]
c3 = barSpaceWidth[index+2]
if c2 > c3:
barCode[i] = 2
else:
barCode[i] = 8
def check_bar_code(barCode):
evens = barCode[11]+barCode[9]+barCode[7]+barCode[5]+barCode[3]+barCode[1]
odds = barCode[10]+barCode[8]+barCode[6]+barCode[4]+barCode[2]+barCode[0]
sum = evens * 3 + odds
if barCode[12] == (10 - sum % 10) % 10:
return True
else:
return False
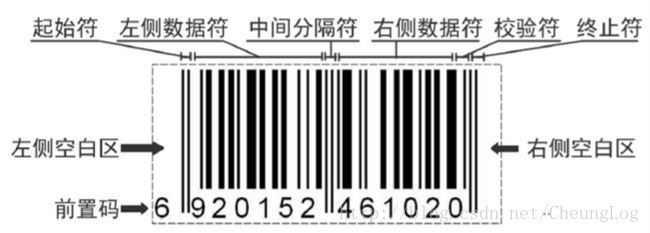
#载入图像
img = cv2.imread('res\google6.jpg')
grayImg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)#转换成单通道图像
ret, grayImg = cv2.threshold(grayImg, 200, 255, cv2.THRESH_BINARY)#二值化
grayImg = cv2.medianBlur(grayImg, 3)#中值滤波
#提取条空宽度
barSpaceWidth = get_bar_space_width(grayImg)
print 'bar & space\'s numbers:', len(barSpaceWidth)#只有60是正确的
print barSpaceWidth
#计算相似边数值
similarEdge = cal_similar_edge(barSpaceWidth)
if similarEdge == -1:
print 'barSpaceWidth error!'
sys.exit()
print 'similarEdge\'s numbers:', len(similarEdge)
print similarEdge
#相似边译码
barCode = decode_similar_edge(similarEdge)
#针对‘#'译码
decode_sharp(barCode, barSpaceWidth)
#校验
valid = check_bar_code(barCode)
valid = 1
print 'barcode:\n', barCode if valid else 'Check barcode error!'
height = img.shape[0]
width = img.shape[1]
cv2.line(grayImg, (0, height/2), (width, height/2),(0, 255, 0), 2)#画出扫描的行
#显示图像
cv2.imshow("origin", img)
cv2.imshow("result", grayImg)
key = cv2.waitKey(0)
if key == 27:
cv2.destroyAllWindows()
|