
使用爬虫时,如果目标网站对访问的速度或次数要求较高,那么你的 IP 就很容易被封掉,也就意味着在一段时间内无法再进行下一步的工作。这时候代理 IP 能够给我们带来很大的便利,不管网站怎么封,只要能找到一个新的代理 IP 就可以继续进行下一步的研究。 目
|
使用爬虫时,如果目标网站对访问的速度或次数要求较高,那么你的 IP 就很容易被封掉,也就意味着在一段时间内无法再进行下一步的工作。这时候代理 IP 能够给我们带来很大的便利,不管网站怎么封,只要能找到一个新的代理 IP 就可以继续进行下一步的研究。
运行结果:
Urllib 使用 ProxyHandler 设置代理,参数是字典类型,键名为协议类型,键值是代理,代理前面需要加上协议,即 http 或 https,当请求的链接是 http 协议的时候,它会调用 http 代理,当请求的链接是 https 协议的时候,它会调用https代理,所以此处生效的代理是:http://108.61.201.231 和 https://108.61.201.231 ProxyHandler 对象创建之后,再利用 build_opener() 方法传入该对象来创建一个 Opener,这样就相当于此 Opener 已经设置好代理了,直接调用它的 open() 方法即可使用此代理访问链接 Requests Requests 的代理设置只需要传入 proxies 参数:
运行结果:
Requests 只需要构造代理字典然后通过 proxies 参数即可设置代理,比较简单 Selenium
运行结果: 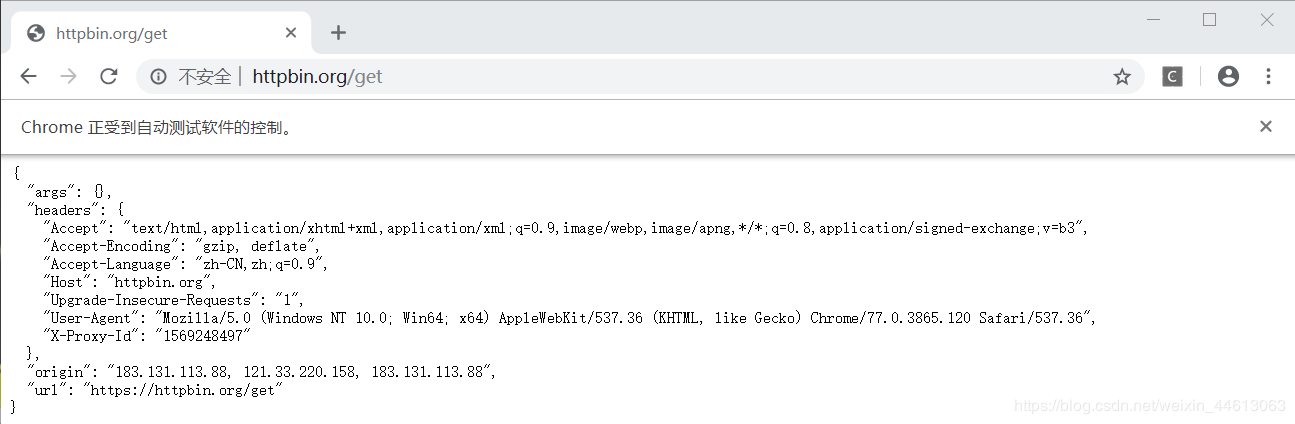 |







2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27






