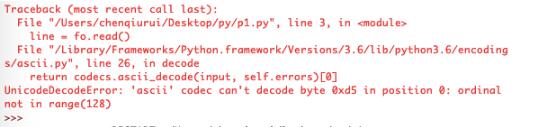
问题描述 尝试用Python写一个Wordcloud的时候,出现了编码问题。 照着网上某些博客的说法添添改改后,结果是变成了UnicodeDecodeError: utf-8 codec cant decode byte这个错误。 捣鼓了一天啊,TXT(此处为本人现下内心表情)。最后,干脆写个最简单的文件读
|
问题描述
照着网上某些博客的说法添添改改后,结果是变成了“UnicodeDecodeError: ‘utf-8' codec can't decode byte…”这个错误。
下面附上第一次成功显示的词云的源码(参考网上他人的,注释很详细)
 |







2019-06-18
2019-07-04
2021-05-23
2021-05-27
2021-05-27