
k8s集群部署时etcd容器不停重启问题以及处理介绍

问题现象 在安装部署Kubernetes 1.26版本时,通过kubeadm初始化集群后,发现执行kubectl命令报以下错误: The connection to the server localhost:8080 was refused - did you specify the right host or port? 查看kub
问题现象在安装部署Kubernetes 1.26版本时,通过kubeadm初始化集群后,发现执行kubectl命令报以下错误:
查看kubelet状态是否正常,发现无法连接apiserver的6443端口。
进而查看apiserver容器的状态,由于是基于containerd作为容器运行时,此时kubectl不可用的情况下,使用crictl ps -a命令可以查看所有容器的情况。
发现此时kube-apiserver容器已经退出,查看容器日志是否有异常信息。通过日志信息发现是kube-apiserver无法连接etcd的2379端口,那么问题应该是出在etcd了。
此时etcd容器也在不断地重启,查看其日志发现没有错误级别的信息。
但是,其中一行日志信息表示etcd收到了关闭的信号,并不是异常退出的。
解决问题该问题为未正确设置cgroups导致,在containerd的配置文件/etc/containerd/config.toml中,修改SystemdCgroup配置为true。
重启containerd服务
etcd容器不再重启,其他容器也恢复正常,问题解决。 |

-
k8s集群部署时etcd容器不停重启问题以及处理介绍
问题现象 在安装部署Kubernetes 1.26版本时,通过kubeadm初始化集群后,发现执行kubectl命令报以下错误: The connection to the server localhost:8080 was -
docker容器中文乱码的解决教程
docker部署java开发web项目。nohup显示打印日志出现中文乱码,中文显示为问号???。 环境 服务器系统:centos7、docker部署项目 具体操作如下 -

云原生Docker创建并进入mysql容器的全过程
本文主要讲解的是创建mysql的容器,大家都知道,在外面进入mysql都很容易,mysql -u用户名 -p密码就可以,但是是容器的mysql就没那么好进入了 -
docker search命令的具体使用
一、docker search 命令选项 命令选项 描述 filter , -f 根据给定的条件进行过滤 format 自定义打印格式 limit 显示搜索结果,默认值25 no-trunc 回显结 -

kvm 透传显卡至win10虚拟机的方法
环境 1 2 3 4 5 6 7 8 9 10 11 已安装nvidia 显卡 驱动 操作系统:CentOS Linux release 7.9.2009 (Core) 内核版本:Linux 5.4.135-1.el7.elrepo.x86_64 显卡 型号:rtx 6000 -
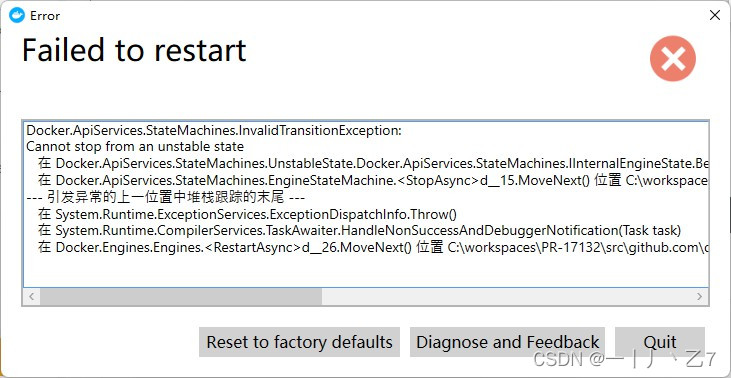
Docker Desktop常见的几种启动失败问题解决方法
报错1,Error:Failed to restart 点Quit 然后出现提示WSL 2 is not installed 点击 Use Hyper-V 打开 启用或关闭windows功能 确保适用于Linux的Windows子系统和 -
使用Kubernetes自定义资源(CRD)的介绍
什么是CRD CRD的全称为CustomResourceDefinitions,即自定义资源。k8s拥有一些内置的资源,比如说Pod,Deployment,ReplicaSet等等,而CRD则提供了一种方



-
详解K8S部署Kafka界面管理工具(kafkama
2022-01-30
-
docker启动jenkins环境的问题介绍
2022-04-01
-
Docker容器搭建Kafka集群的教程
2022-03-20
-
KVM介绍及作用
2022-03-20
-
详解Docker容器之间数据传输
2022-03-20

