Flink 的 side output 为我们提供了侧流(分流)输出的功能,根据条件可以把一条流分为多个不同的流,之后做不同的处理逻辑,下面就来看下侧流输出相关的源码。 先来看下面的一个
|
Flink 的 side output 为我们提供了侧流(分流)输出的功能,根据条件可以把一条流分为多个不同的流,之后做不同的处理逻辑,下面就来看下侧流输出相关的源码。 先来看下面的一个 Demo,一个流被分成了 3 个流,一个主流,两个侧流输出。
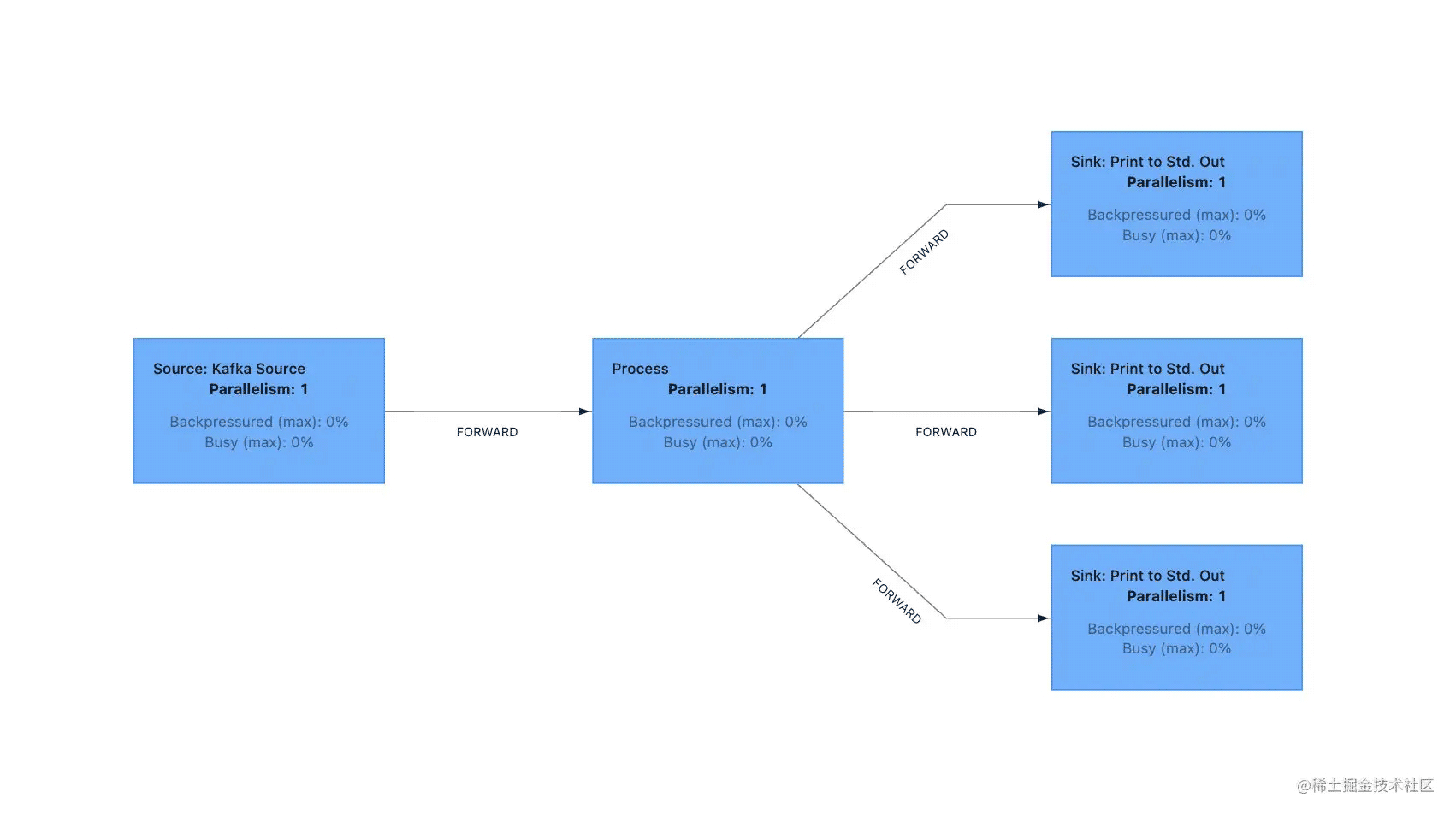
为了更加清楚的查看每一个算子,我禁用了 operator chain,任务的 DAG 图如下所示:
这样就比较清晰了,很明显从 process 算子开始,1 个数据流分为了 3 个数据流,当然,在默认情况下没有禁止 operator chain 所有的算子都是 chain 在一起的。 源码解析我们先来看第一个主流输出也就是 out.collect(value) 的源码,这里的 out 实际上是 TimestampedCollector 对象。 TimestampedCollector#collect
在 collect 方法中持有一个 output 对象,用来输出数据,在这里实际上是一个 CountingOutput 它是一个包装了 Output 的对象,主要用于更新发送数据的 metric,并输出数据。 CountingOutput#collect
在 CountingOutput 中也持有一个 output 对象,但是这里的 output 是 BroadcastingOutputCollector 对象,从名字就可以看出它是往下游广播数据的,这里就有一个疑问?把数据广播到下游,那岂不是下游的每个数据流都有这条数据吗?这样的话是怎么实现分流的呢?带着这个疑问,我们来看 BroadcastingOutputCollector 的 collect 方法是怎么实现的。 BroadcastingOutputCollector#collect
在 BroadcastingOutputCollector 对象里也持有一个 output 对象,其实他们都实现了 Output 接口,用来往下游发送数据,这里的 outputs 是一个 Output 数组,代表了下游的所有 Output,因为上面有三个输出流,所以数组里面就包含了 3 个 Output 对象。 循环的调用 output 的 collect 方法往下游发送数据,因为我打断了 operator chain,所以 process 算子和下游的 Print 算子不在同一个 operatorChain 内,那么上下游算子之间数据传输用的就是 RecordWriterOutput,否则用的是 CopyingChainingOutput 或者 ChainingOutput,具体使用的是哪个 Output 这里就不多介绍了,后面有时间的话会单独介绍。 RecordWriterOutput#collect
接着来看 RecordWriterOutput 的 collect 方法,在 collect 方法里面会先判断 outputTag 是否为空,如果不为空不做任何处理,直接返回,否则就把数据推送到下游算子,只有侧流输出才需要定义 outputTag,主流(正常流)是没有 outputTag 的,所以这里会走 pushToRecordWriter 方法把数据写入到下游,也就是说虽然会以广播的形式把数据广播到所有下游,但其实另外两个侧流是直接返回的,只有主流才会把数据推送到下游,这也就解释了上面的疑问。 然后再来看第二个侧流输出 ctx.output(test, value) 的源码,这里的 ctx 实际上是 ProcessOperator#ContextImpl 对象。 ProcessOperator#ContextImpl#output
如果 outputTag 是空,直接抛出异常,因为这个是侧流,所以必须要定义 OutputTag。这里的 output 实际上是父类 AbstractStreamOperator 所持有的变量,如果 outputTag 不为空,就调用 output 的 collect 方法把数据发送到下游,这里的 output 和上面的一样是 CountingOutput 但是 collect 方法是另外一个重载的方法。 CountingOutput#collect
可以发现,这个 collect 方法比上面那个多了一个 OutputTag 参数,也就是使用侧流输出的时候定义的 OutputTag 对象,然后调用 output 的 collect 方法发送数据,这个也和上面的一样,同样是 BroadcastingOutputCollector 对象的另外一个重载方法,多了一个 OutputTag 参数。 BroadcastingOutputCollector#collect
这里的逻辑和上面是一样的,同样的循环调用 collect 方法发送数据。 RecordWriterOutput#collect
在这个 collect 方法中会先判断传入的 OutputTag 对象和成员变量 this.outputTag 是不是相等,如果是的话,就发送数据,否则不做任何处理,所以这里每次只会选择一个下游侧流输出数据,这样就实现了所谓的分流。 OutputTag#isResponsibleFor
可以看到在 isResponsibleFor 方法内是直接调用 OutputTag 的 equals 方法判断两个对象是否相等的。 第三个侧流 test1 ctx.output(test1, value) 和第二个侧流 test 是完全一样的情况,这里就不在看代码了。 上面是完成了分流操作,那怎么获取到分流后结果呢(数据流)?我们可以通过 getSideOutput 方法获取。
getSideOutput 源码
getSideOutput 方法里先是构建了一个 SideOutputTransformation 对象,然后又构建了 DataStream 对象,这样我们就可以基于分流后的 DataStream 做不同的处理逻辑了,从而实现了把一个 DataStream 分流成多个 DataStream 功能。 总结通过对侧流输出的源码进行解析,在分流的时候,数据是通过广播的方式发送到下游算子的,对于主流的数据来说,只有 OutputTag 为空的才会处理,侧流因为 OutputTag 不为空,所以直接返回,不做任何处理,那对于侧流的数据来说,是通过判断两个 OutputTag 是否相等,所以每次只会把数据发送到下游对应的那一个侧流上去,这样即可实现分流逻辑。 |




2022-08-26
2022-09-23
2022-09-30
2022-09-23
2022-09-17