本篇文章记录最近一次生产服务器硬件升级之后引起集群不稳定的现象,希望可以帮到有其它人避免采坑。 一、问题描述 升级后出现的异常如下: 出现限流日志:stop throttling indexing
|
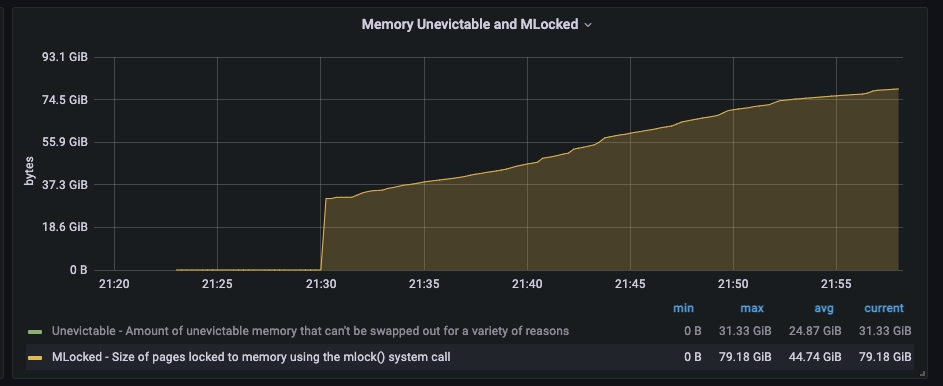
本篇文章记录最近一次生产服务器硬件升级之后引起集群不稳定的现象,希望可以帮到有其它人避免采坑。 一、问题描述升级后出现的异常如下: 出现限流日志:stop throttling indexing: numMergesInFlight=8, maxNumMerges=9应用写入集群的rt耗时变高,同时集群监控的indexing的时长也变高mlocked的内存调用一直在增长
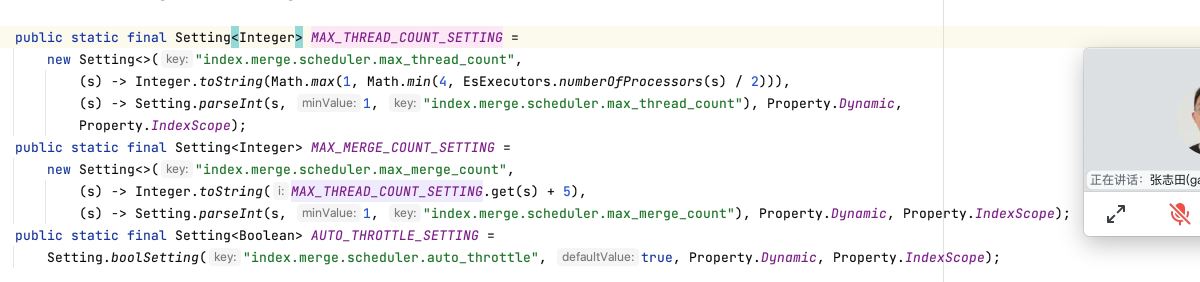
二、升级过程升配前ES version:6.2.4 配置:32C64G 环境:阿里云ecs自建 gc:cms jvm:30GB 升配后 ES version:6.2.4 配置:64C128G 环境:阿里云ecs自建 gc:cms jvm:30GB 三、处理步骤升配之后第二天首先应用表现出异常,写入ES的耗时变高了好十几倍,从40ms上升到600ms;升配导致集群变慢还是头一次遇到。通过对集群监控分析集群整体负载正常比升配之前有所下降,但是indexing的写入耗时监控确实比升配之前增长了很多。在ES的输出日志中出现了异常日志"stop throttling indexing: numMergesInFlight=8, maxNumMerges=9"; 1.限流处理当时怀疑应该是这个限流导致,ES的限流的主要目的是出于对集群的保护避免产生过多的段影响性能,说白了就是段的合并跟不上写入的速度,所以先来解决这个限流的问题, 由于配置文件没有配置最大线程数和最大的合并线程数,所以这两个值是用的是默认值
注意:在6.x版本之后已经取消了"indices.store.throttle.max_bytes_per_sec",所以现在只能通过调整max_thread_count,max_merge_count,默认max_thread_count最小是1最大是4,如果是机械盘推荐设1如果是ssd盘可以设成4或者更高,max_merge_count默认等于max_thread_count+5,也可以单独设置 可以通过命令查看默认的集群参数配置:
可以配置到配置文件当中,也可以通过以下命令针对索引进行动态设置:
2.mlock通过修改线程数之后,限流的问题解决了,但是应用的写入rt耗时问题还是没有得到解决 。通过对"hot_threads"进行分析发现主要的耗时还是在merge和index两大块,并且通过os层面的监控发现mlock的占用内存一直在增长,启动参数配置文件设置在内存锁定“bootstrap.memory_lock: true”不明白为什么还会出现mlock的增长。 处理办法: 将硬件配置降回到32C64G问题解决,增加一副本来提升查询性能 3、总结经过3天问题排查,网上也没有找到类似的案例,网上更多的还是限流相关的案例,总结下来应该还是当前版本对于大内存的处理相关的bug,在7.x版本没有出现类似的内存问题 |




2022-08-26
2022-09-23
2022-09-30
2022-09-23
2022-09-17